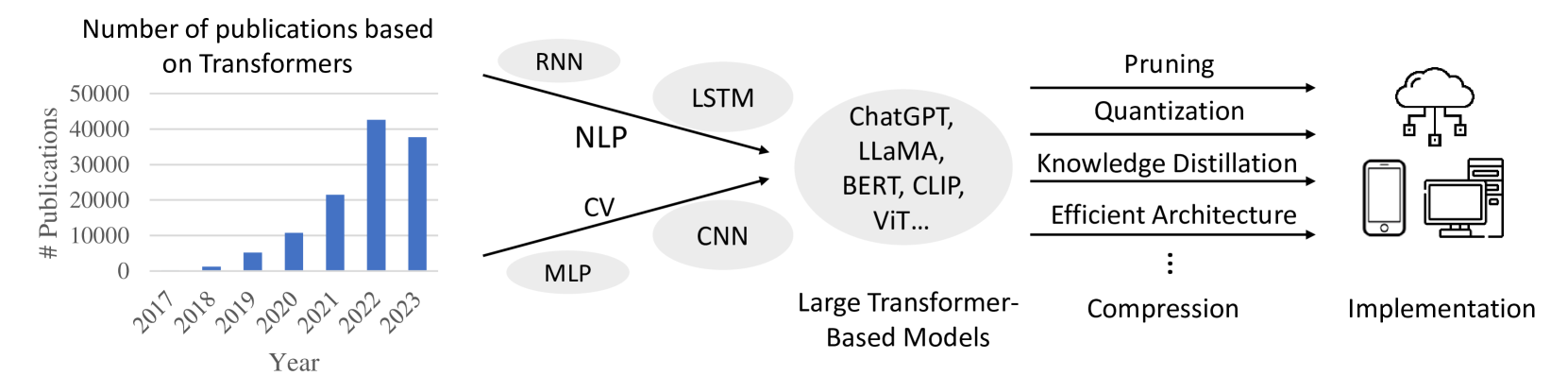
## Chart/Diagram Type: Transformer Publication Trend and Model Compression Pipeline
### Overview
The image presents a combination of a bar chart illustrating the increasing number of publications based on Transformers over the years, and a diagram depicting the pipeline from various neural network architectures to large transformer-based models, their compression techniques, and final implementation.
### Components/Axes
**Bar Chart:**
* **Title:** Number of publications based on Transformers
* **Y-axis:** # Publications, ranging from 0 to 50000, with increments of 10000.
* **X-axis:** Year, ranging from 2017 to 2023.
**Diagram:**
* **Input Models:** RNN, LSTM, CNN, MLP
* **Intermediate Stage:** Large Transformer-Based Models (ChatGPT, LLaMA, BERT, CLIP, ViT...)
* **Compression Techniques:** Pruning, Quantization, Knowledge Distillation, Efficient Architecture
* **Output:** Implementation (Cloud, Mobile, Desktop)
### Detailed Analysis or ### Content Details
**Bar Chart Data:**
* **2017:** Approximately 0 publications.
* **2018:** Approximately 1000 publications.
* **2019:** Approximately 5000 publications.
* **2020:** Approximately 8000 publications.
* **2021:** Approximately 11000 publications.
* **2022:** Approximately 21000 publications.
* **2023:** Approximately 42000 publications.
**Diagram Flow:**
1. **Input Models:**
* RNN and LSTM are associated with NLP (Natural Language Processing).
* CNN and MLP are associated with CV (Computer Vision).
2. **Large Transformer-Based Models:**
* The input models feed into a stage of Large Transformer-Based Models, including examples such as ChatGPT, LLaMA, BERT, CLIP, and ViT.
3. **Compression Techniques:**
* These large models are then subjected to compression techniques like Pruning, Quantization, Knowledge Distillation, and Efficient Architecture.
4. **Implementation:**
* Finally, the compressed models are implemented on various platforms, including cloud, mobile devices, and desktop computers.
### Key Observations
* The number of publications based on Transformers has increased exponentially from 2017 to 2023.
* The diagram illustrates a common pipeline for developing and deploying large transformer-based models, emphasizing the importance of compression techniques for practical implementation.
### Interpretation
The data suggests a rapidly growing interest and research activity in the field of Transformers. The diagram highlights the progression from traditional neural network architectures to large transformer models, and the necessity of model compression to enable deployment on diverse platforms. The exponential increase in publications likely reflects the increasing capabilities and applications of transformer-based models in various domains. The diagram shows the flow from initial models (RNN, LSTM, CNN, MLP) to large transformer models, and then to compressed implementations. This indicates a trend towards more complex models that require optimization for real-world use.