\n
## Diagram: Transformer Publication Growth & Implementation
### Overview
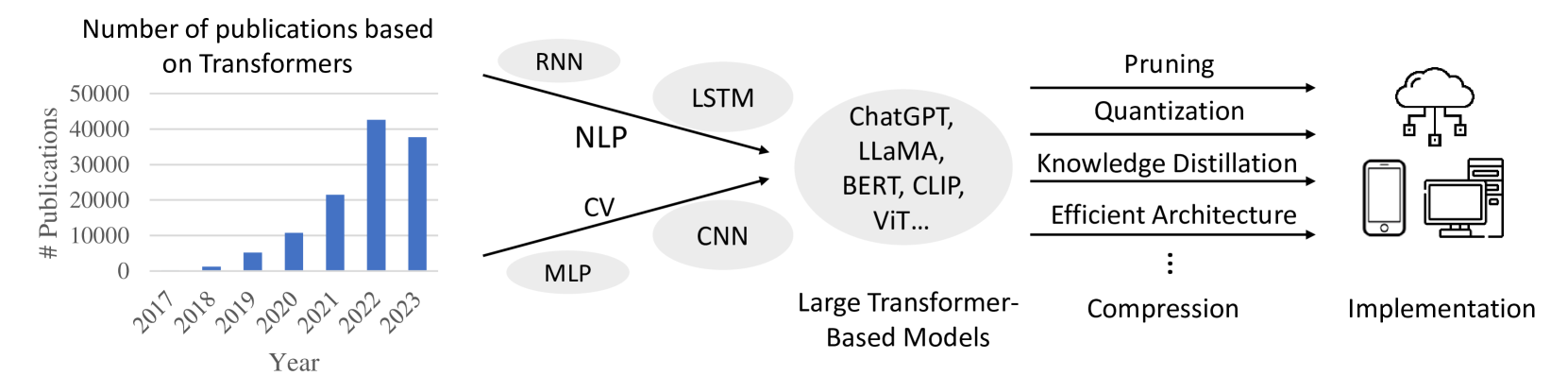
The image is a diagram illustrating the growth in publications related to Transformer models from 2017 to 2023, and the subsequent methods for implementing these models. The diagram is split into three main sections: a bar chart showing publication numbers, a central node representing Large Transformer-Based Models and their connections to various NLP and CV architectures, and a right-hand side depicting implementation techniques.
### Components/Axes
* **Left Section (Bar Chart):**
* X-axis: Year (2017, 2018, 2019, 2020, 2021, 2022, 2023)
* Y-axis: # Publications (Scale from 0 to 50000)
* **Central Section (Node Diagram):**
* Central Node: "Large Transformer-Based Models"
* Connected Nodes: "NLP", "CV"
* Sub-Nodes (connected to NLP): "RNN", "LSTM"
* Sub-Nodes (connected to CV): "CNN"
* Additional Node: "MLP"
* Examples within the "Large Transformer-Based Models" node: "ChatGPT, LLaMA, BERT, CLIP, ViT..."
* **Right Section (Implementation):**
* "Compression"
* "Implementation"
* Compression Techniques: "Pruning", "Quantization", "Knowledge Distillation", "Efficient Architecture", "..."
* Arrows indicate flow/relationship between components.
### Detailed Analysis or Content Details
* **Publication Growth (Bar Chart):**
* 2017: Approximately 1000 publications.
* 2018: Approximately 2000 publications.
* 2019: Approximately 4000 publications.
* 2020: Approximately 12000 publications.
* 2021: Approximately 25000 publications.
* 2022: Approximately 35000 publications.
* 2023: Approximately 33000 publications.
* The trend shows a steep increase in publications from 2017 to 2022, with a slight decrease in 2023.
* **Model Architecture Connections:**
* NLP (Natural Language Processing) is connected to RNN (Recurrent Neural Networks) and LSTM (Long Short-Term Memory).
* CV (Computer Vision) is connected to CNN (Convolutional Neural Networks).
* MLP (Multilayer Perceptron) is directly connected to "Large Transformer-Based Models".
* **Implementation Flow:**
* "Large Transformer-Based Models" are compressed using techniques like Pruning, Quantization, Knowledge Distillation, and Efficient Architecture.
* Compressed models are then implemented, with icons representing cloud servers and mobile devices.
### Key Observations
* The number of publications on Transformers has increased dramatically in recent years, peaking in 2022.
* Transformers are being applied to both NLP and CV tasks, leveraging existing architectures like RNNs, LSTMs, and CNNs.
* Model compression is a crucial step in deploying large Transformer models, enabling implementation on resource-constrained devices.
* The diagram highlights the progression from research (publications) to practical application (implementation).
### Interpretation
The diagram illustrates the rapid growth and increasing importance of Transformer-based models in the field of artificial intelligence. The surge in publications indicates a high level of research activity and innovation. The connections between Transformers and established architectures suggest that Transformers are not replacing existing methods entirely, but rather building upon them. The emphasis on model compression highlights the challenges of deploying these large models in real-world applications, and the need for efficient implementation strategies. The inclusion of cloud and mobile device icons suggests a desire to make these models accessible across a wide range of platforms. The slight dip in publications in 2023 could indicate a maturation of the field, with a shift from rapid exploration to more focused refinement and application. The diagram effectively communicates the lifecycle of Transformer models, from initial research to practical deployment.