\n
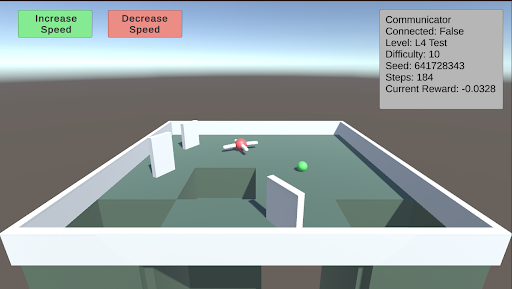
## Screenshot: AI Agent Simulation Environment
### Overview
This image is a screenshot from a 3D simulation environment, likely used for training or testing an AI agent (represented by a drone). The scene depicts a simple maze with a drone, a target object, and a user interface (UI) overlay containing control buttons and a status information panel.
### Components/Axes
The image is divided into two primary regions: the 3D simulation viewport and the 2D UI overlay.
**1. UI Overlay (Top Region):**
* **Top-Left Corner:** Two rectangular buttons.
* **Left Button:** Green background. Text: "Increase Speed".
* **Right Button:** Red background. Text: "Decrease Speed".
* **Top-Right Corner:** A semi-transparent grey information panel titled "Communicator". It contains the following key-value pairs:
* `Communicator`
* `Connected: False`
* `Level: L4 Test`
* `Difficulty: 1.0`
* `Seed: 641728343`
* `Step: 14`
* `Current Reward: -0.0328`
**2. 3D Simulation Viewport (Main Region):**
* **Environment:** A square arena with low, white perimeter walls. The floor is a flat, green surface.
* **Structures:** Several white, rectangular walls are placed within the arena, creating a simple maze or obstacle course. There are at least two distinct open pits or holes in the floor, appearing as dark green recessed areas.
* **Agents/Objects:**
* **Drone:** A small, red and white quadcopter-style drone is positioned near the center of the arena, slightly to the left. It appears to be hovering or resting on the floor.
* **Target Sphere:** A small, bright green sphere is located on the floor to the right of the drone.
### Detailed Analysis
* **Spatial Layout:** The drone is positioned approximately 1/3 from the left edge and centered vertically in the viewport. The green sphere is about 2/3 from the left edge, slightly lower than the drone. The two largest pits are in the foreground (bottom of the viewport) and to the left of the drone.
* **UI State:** The "Communicator" panel indicates the simulation is active but not connected to an external system (`Connected: False`). The agent is on step 14 of an episode in a test level ("L4 Test") with a fixed random seed (`641728343`). The current cumulative reward is negative (`-0.0328`), suggesting the agent has incurred penalties, possibly for time elapsed or inefficient movement.
* **Visual Style:** The graphics are simple and low-poly, characteristic of a research or development simulation environment (e.g., Unity, MuJoCo). Lighting is flat with soft shadows.
### Key Observations
1. **Agent Status:** The drone is stationary or moving slowly near the center of the maze. Its proximity to the green sphere (likely a goal or target) is notable.
2. **Negative Reward:** The negative reward value (`-0.0328`) at step 14 is a critical data point. It implies the agent's policy is currently suboptimal, as it is accumulating penalties rather than positive rewards.
3. **Environment Hazards:** The presence of open pits suggests a navigation challenge where falling in would likely result in a large negative reward or episode termination.
4. **Control Interface:** The "Increase/Decrease Speed" buttons imply this is a interactive debugging or visualization tool, allowing a human observer to control the simulation speed.
### Interpretation
This screenshot captures a moment in a reinforcement learning or robotics simulation. The **"L4 Test"** level with a **"Difficulty: 1.0"** and a specific **"Seed"** indicates a controlled, reproducible experiment. The agent (drone) is tasked with navigating the maze, likely to reach the green sphere while avoiding pits.
The **negative reward** is the most significant piece of data. It suggests that within the first 14 steps, the agent has either:
* Remained idle (incurring a time penalty).
* Moved inefficiently.
* Possibly collided with a wall or fallen into a pit (though its current position on the floor makes this less likely at this exact step).
The **"Connected: False"** status means this is a local simulation run, not being controlled by or streaming data to an external learning algorithm at this moment. The setup is typical for evaluating a pre-trained policy or debugging environment mechanics. The visual evidence points to a standard test scenario in AI research for embodied agents, where the core challenge is spatial reasoning and reward optimization.