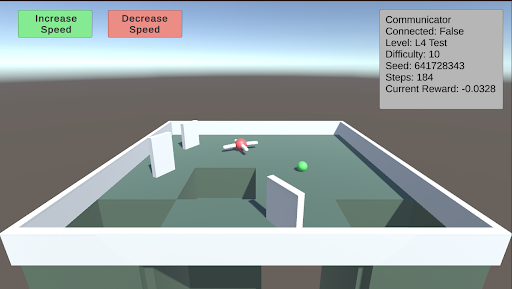
## Screenshot: Reinforcement Learning Simulation Environment
### Overview
The image depicts a 3D simulation environment for a reinforcement learning task. The scene includes a rectangular arena with geometric obstacles, a movable red object (likely an agent), and a green spherical target. UI elements provide real-time feedback about the simulation state.
### Components/Axes
**Top UI Elements:**
- **Buttons (Top-Left Corner):**
- Green button labeled "Increase Speed"
- Red button labeled "Decrease Speed"
- **Status Panel (Top-Right Corner):**
- Text labels with key-value pairs:
- `Communicator Connected: False`
- `Level: L4 Test`
- `Difficulty: 10`
- `Seed: 641728343`
- `Steps: 184`
- `Current Reward: -0.0328`
**Main Arena:**
- **Geometry:**
- Rectangular enclosure with white barriers
- Green floor surface
- Three white rectangular obstacles (positions: left, center-left, and right-center)
- **Objects:**
- Red spherical object (agent) at coordinates (~0.5, 0.3, 0.1)
- Green spherical target at coordinates (~0.7, 0.6, 0.1)
### Detailed Analysis
**UI Text Extraction:**
- All text is in English, using Arial-like font.
- Numerical values:
- Seed: `641728343` (32-bit integer)
- Steps: `184` (episode progress)
- Reward: `-0.0328` (floating-point, negative value)
**Spatial Grounding:**
- Buttons occupy top-left quadrant (15% width, 10% height)
- Status panel occupies top-right quadrant (20% width, 15% height)
- Arena occupies central 70% of the image
- Red object positioned at ~30% width, ~40% height
- Green target positioned at ~60% width, ~50% height
### Key Observations
1. **Negative Reward:** The agent's current performance is suboptimal (reward < 0)
2. **Obstacle Configuration:** Three barriers create a maze-like environment
3. **Disconnected Communicator:** Simulation running in offline/debug mode
4. **Seed Value:** Unique identifier for reproducibility (641728343)
5. **Difficulty Level:** Medium complexity (level 4 test)
### Interpretation
This appears to be a training/test environment for a robotic navigation task. The negative reward suggests the agent has not yet learned to reach the green target. The disconnected communicator indicates this is likely a local simulation rather than a networked system. The seed value allows researchers to reproduce identical conditions for debugging. The difficulty level (10) and step count (184) suggest this is a mid-progress test case, with the agent having explored ~184 possible actions without achieving the goal. The geometric obstacles create a spatial reasoning challenge, requiring the agent to navigate around barriers while optimizing path efficiency.