## Bar Chart: Percent of Incorrect Answers by Grounding Type
### Overview
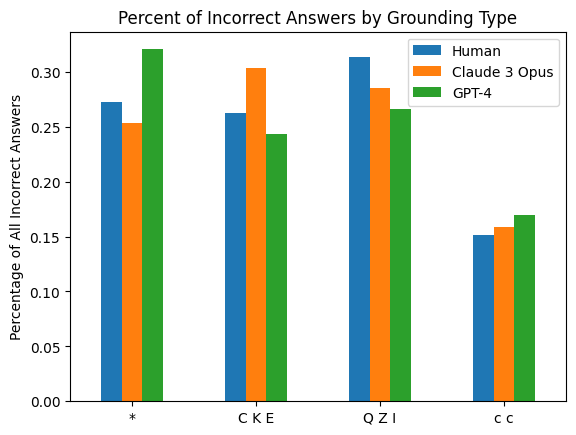
The chart compares the percentage of incorrect answers across three groups (Human, Claude 3 Opus, GPT-4) for four grounding types: *, CKE, QZI, and c c. Values are represented as vertical bars with approximate percentages on the y-axis (0.00–0.30).
### Components/Axes
- **X-axis (Grounding Type)**: Four categories: `*`, `CKE`, `QZI`, `c c` (left to right).
- **Y-axis (Percentage of All Incorrect Answers)**: Scale from 0.00 to 0.30 in increments of 0.05.
- **Legend**: Located in the top-right corner, mapping colors to groups:
- Blue: Human
- Orange: Claude 3 Opus
- Green: GPT-4
### Detailed Analysis
1. **Grounding Type `*`**:
- Human: ~0.27
- Claude 3 Opus: ~0.25
- GPT-4: ~0.32 (highest)
2. **Grounding Type `CKE`**:
- Human: ~0.26
- Claude 3 Opus: ~0.30 (highest)
- GPT-4: ~0.24 (lowest)
3. **Grounding Type `QZI`**:
- Human: ~0.31 (highest)
- Claude 3 Opus: ~0.28
- GPT-4: ~0.26
4. **Grounding Type `c c`**:
- Human: ~0.15
- Claude 3 Opus: ~0.16
- GPT-4: ~0.17 (highest)
### Key Observations
- **GPT-4** consistently shows the highest error rates in `*` and `c c`, while **Claude 3 Opus** peaks in `CKE`.
- **Human** has the highest error rate in `QZI` (~0.31), significantly above other groups.
- **Claude 3 Opus** and **GPT-4** have the lowest error rates in `c c` (~0.16 and ~0.17, respectively).
### Interpretation
The data suggests that model performance varies significantly depending on grounding type. GPT-4 appears less accurate in `*` and `c c`, while Claude 3 Opus struggles most with `CKE`. Humans exhibit the highest errors in `QZI`, potentially indicating task-specific challenges. The disparity in error rates across models and grounding types highlights the importance of grounding type in evaluating AI performance, with no single model consistently outperforming others across all categories.