## Line Graph: Model Performance vs Training Tokens
### Overview
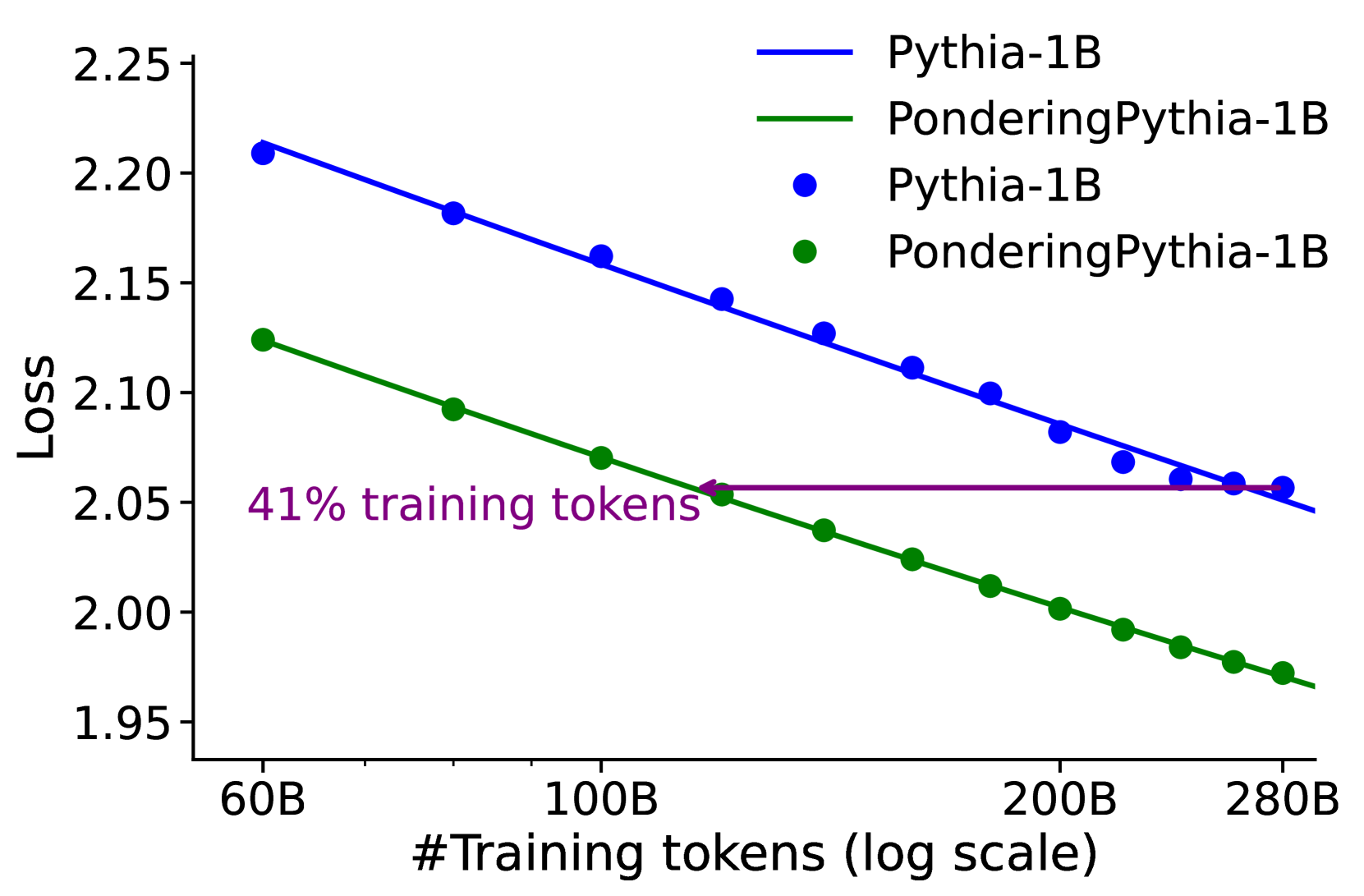
The graph compares the loss reduction of two language models (Pythia-1B and PonderingPythia-1B) as a function of training tokens on a logarithmic scale. Two lines represent model performance, with a horizontal purple line marking a 41% training token threshold.
### Components/Axes
- **X-axis**: "#Training tokens (log scale)" ranging from 60B to 280B (60B, 100B, 200B, 280B).
- **Y-axis**: "Loss" ranging from 1.95 to 2.25.
- **Legend**:
- Blue line: Pythia-1B
- Green line: PonderingPythia-1B
- **Key annotations**: Purple horizontal line labeled "41% training tokens" at ~100B on the x-axis.
### Detailed Analysis
1. **Pythia-1B (Blue Line)**:
- Starts at ~2.20 loss at 60B tokens.
- Decreases linearly to ~2.05 loss at 280B tokens.
- Slope: Steady decline (~0.005 loss per 10B tokens).
2. **PonderingPythia-1B (Green Line)**:
- Starts at ~2.12 loss at 60B tokens.
- Decreases more steeply than Pythia-1B, reaching ~1.97 loss at 280B tokens.
- Intersects the 41% training tokens marker (~100B) at ~2.05 loss.
3. **41% Training Tokens Marker**:
- Horizontal purple line at ~100B tokens.
- Green line crosses this threshold at ~2.05 loss, while Pythia-1B remains at ~2.10 loss.
### Key Observations
- Both models show **inverse scaling**: loss decreases as training tokens increase.
- PonderingPythia-1B achieves **~15% lower loss** than Pythia-1B at 280B tokens.
- The 41% threshold (~100B tokens) marks a **performance inflection point** for PonderingPythia-1B.
### Interpretation
The graph demonstrates that PonderingPythia-1B exhibits superior training efficiency, achieving lower loss with fewer tokens. The 41% threshold likely represents a critical training milestone where the model's architecture or optimization strategy becomes more effective. The logarithmic x-axis emphasizes diminishing returns at higher token counts, suggesting that early-stage training (below 100B tokens) is disproportionately impactful for loss reduction. This aligns with findings in large language model training, where initial parameter tuning often yields the most significant performance gains.