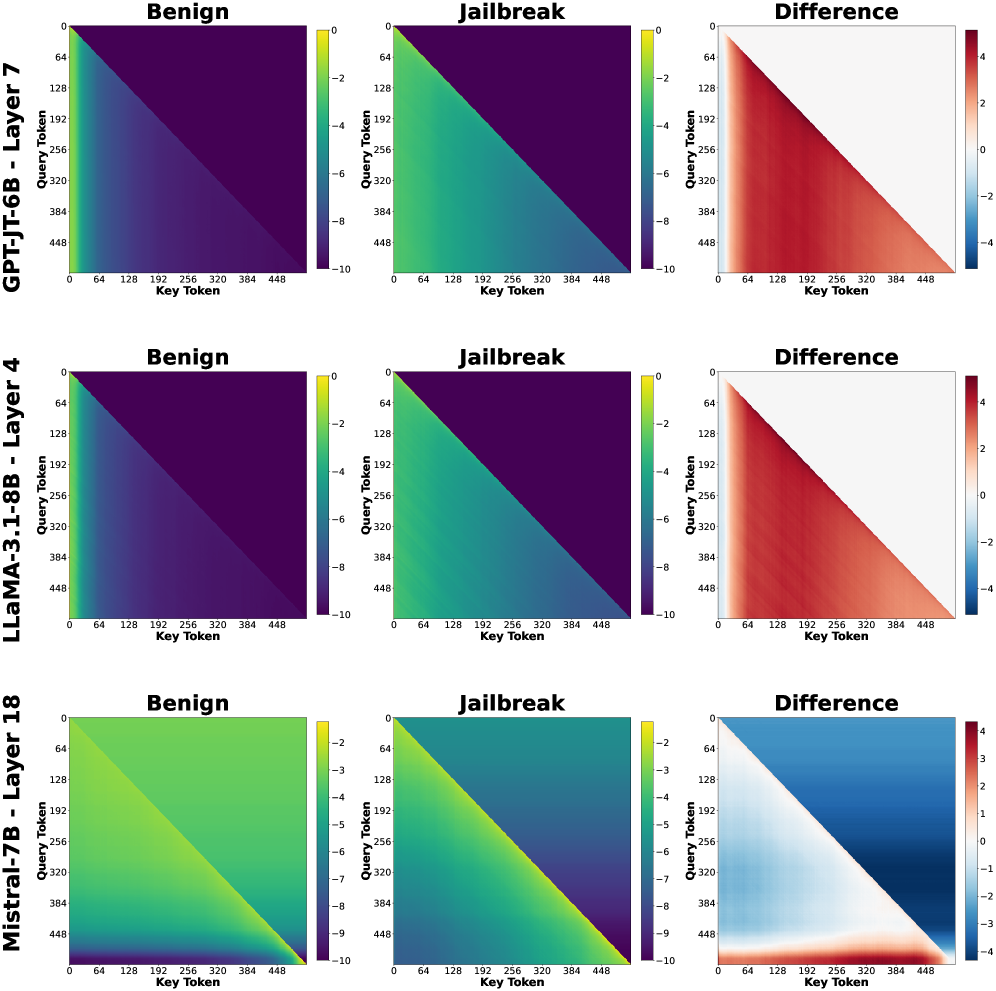
## Heatmap Comparison: Model Behavior on Benign vs. Jailbreak Prompts
### Overview
The image presents a series of heatmaps comparing the behavior of three different language models (GPT-JT-6B, LLaMA-3.1-8B, and Mistral-7B) when processing benign and jailbreak prompts. Each row corresponds to a different model, and each column represents a different condition: "Benign" prompt, "Jailbreak" prompt, and the "Difference" between the two. The heatmaps visualize the interaction between "Query Token" and "Key Token" within specific layers of each model.
### Components/Axes
* **Rows (Models):**
* GPT-JT-6B - Layer 7
* LLaMA-3.1-8B - Layer 4
* Mistral-7B - Layer 18
* **Columns (Conditions):**
* Benign
* Jailbreak
* Difference
* **X-axis (Key Token):** Ranges from 0 to 448, with tick marks at 0, 64, 128, 192, 256, 320, 384, and 448.
* **Y-axis (Query Token):** Ranges from 0 to 448, with tick marks at 0, 64, 128, 192, 256, 320, 384, and 448.
* **Color Scale (Benign & Jailbreak):** Ranges from -10 (dark purple) to 0 (yellow).
* **Color Scale (Difference):** Ranges from -4 (dark blue) to 4 (dark red), with 0 being white.
### Detailed Analysis
**GPT-JT-6B - Layer 7**
* **Benign:** The heatmap shows a gradient, with values decreasing from yellow (0) at the top-left corner to dark purple (-10) towards the bottom-right.
* **Jailbreak:** Similar to the "Benign" condition, the heatmap shows a gradient from yellow (0) to dark purple (-10).
* **Difference:** The heatmap shows a clear separation. The upper-left triangle is predominantly blue (negative difference), while the lower-right triangle is predominantly red (positive difference).
**LLaMA-3.1-8B - Layer 4**
* **Benign:** Similar to GPT-JT-6B, the heatmap shows a gradient from yellow (0) to dark purple (-10).
* **Jailbreak:** Similar to the "Benign" condition, the heatmap shows a gradient from yellow (0) to dark purple (-10).
* **Difference:** The heatmap shows a clear separation. The upper-left triangle is predominantly blue (negative difference), while the lower-right triangle is predominantly red (positive difference).
**Mistral-7B - Layer 18**
* **Benign:** The heatmap shows a gradient, with values decreasing from yellow (0) at the top-left corner to dark purple (-10) towards the bottom-right.
* **Jailbreak:** Similar to the "Benign" condition, the heatmap shows a gradient from yellow (0) to dark purple (-10).
* **Difference:** The heatmap shows a clear separation. The upper-left triangle is predominantly blue (negative difference), while the lower-right triangle is predominantly red (positive difference).
### Key Observations
* The "Benign" and "Jailbreak" heatmaps for each model are visually similar, suggesting that the overall attention patterns are not drastically different between the two conditions.
* The "Difference" heatmaps highlight specific regions where the attention patterns diverge between the "Benign" and "Jailbreak" prompts.
* The "Difference" heatmaps consistently show a separation, with negative differences (blue) in the upper-left triangle and positive differences (red) in the lower-right triangle.
### Interpretation
The heatmaps visualize the attention patterns within different layers of the language models when processing benign and jailbreak prompts. The similarity between the "Benign" and "Jailbreak" heatmaps suggests that the overall attention mechanisms are not fundamentally altered by the jailbreak prompts. However, the "Difference" heatmaps reveal subtle but significant variations in attention patterns.
The consistent separation observed in the "Difference" heatmaps, with negative differences in the upper-left triangle and positive differences in the lower-right triangle, indicates that the jailbreak prompts may be causing the models to shift their attention towards different tokens or regions within the input sequence. This shift in attention could be a contributing factor to the models' susceptibility to jailbreak attacks.
The specific layers chosen for analysis (Layer 7 for GPT-JT-6B, Layer 4 for LLaMA-3.1-8B, and Layer 18 for Mistral-7B) may represent layers where these differences are most pronounced. Further investigation could explore other layers to understand the full extent of the attention pattern variations.