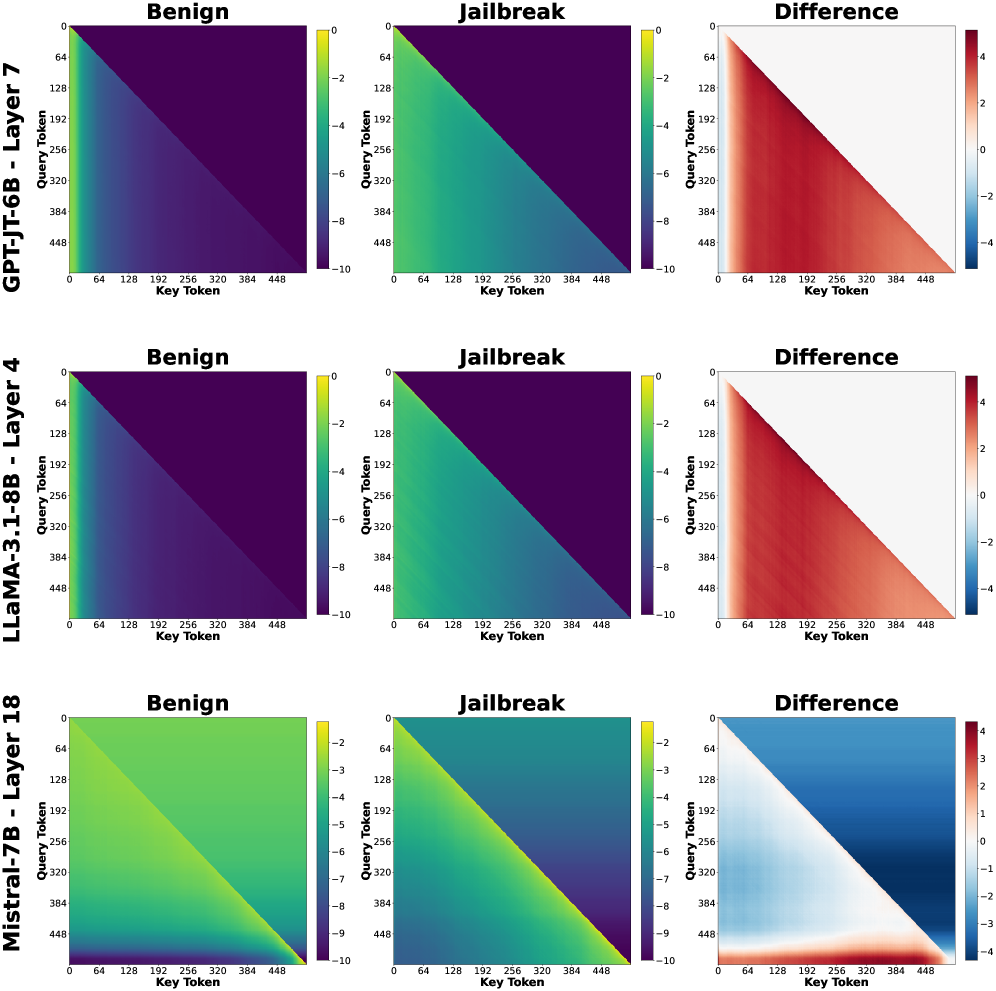
\n
## Heatmaps: Activation Patterns for Language Models
### Overview
The image presents a 3x3 grid of heatmaps, visualizing activation patterns for three different language models (GPT-J 6B, LLaMA-3 1.8B, and Mistral 7B) under two conditions: "Benign" and "Jailbreak". The third heatmap in each row shows the "Difference" between the "Benign" and "Jailbreak" activations. Each heatmap plots activation values against "Key Token" and "Query Token" dimensions.
### Components/Axes
Each heatmap shares the following components:
* **Title:** Indicates the model and layer being visualized (e.g., "GPT-J 6B - Layer 7").
* **X-axis:** Labeled "Key Token", ranging from 0 to 448, with markers at intervals of 64.
* **Y-axis:** Labeled "Query Token", ranging from 0 to 448, with markers at intervals of 64.
* **Color Scale:** A continuous color scale ranging from approximately -10 to 4, with colors transitioning from dark purple/blue (low values) to yellow/red (high values).
* **Sub-Titles:** "Benign", "Jailbreak", and "Difference" indicate the condition being visualized.
### Detailed Analysis or Content Details
**Row 1: GPT-J 6B - Layer 7**
* **Benign:** A diagonal band of high activation (yellow/red) extends from the bottom-left to the top-right corner. Values appear to peak around 3-4. Activation is low (dark purple) elsewhere.
* **Jailbreak:** A mostly uniform dark purple/blue color indicates low activation across the entire heatmap. There's a slight diagonal band of slightly higher activation (purple) but significantly lower than the "Benign" case. Values are around -2 to -8.
* **Difference:** A diagonal band of positive values (yellow/red) mirrors the "Benign" heatmap, indicating a significant increase in activation in this region when the input is benign. Values range from approximately -2 to 4.
**Row 2: LLaMA-3 1.8B - Layer 4**
* **Benign:** A strong diagonal band of high activation (yellow/red) is present, similar to GPT-J, but more concentrated. Values peak around 3-4.
* **Jailbreak:** Predominantly dark purple/blue, indicating low activation. A faint diagonal band of slightly higher activation (purple) is visible. Values are around -2 to -8.
* **Difference:** A diagonal band of positive values (yellow/red) corresponds to the "Benign" heatmap, showing increased activation in the same region. Values range from approximately -2 to 4.
**Row 3: Mistral 7B - Layer 18**
* **Benign:** A diagonal band of high activation (yellow/red) is present, but it's broader and less sharply defined than in the other models. Values peak around 3-4.
* **Jailbreak:** A diagonal band of negative activation (dark blue/purple) is visible, contrasting with the "Benign" case. Values range from approximately -10 to -2.
* **Difference:** A diagonal band of positive values (yellow/red) indicates increased activation in the same region as the "Benign" heatmap. Values range from approximately -2 to 4.
### Key Observations
* All three models exhibit a strong diagonal activation pattern in the "Benign" condition.
* The "Jailbreak" condition consistently results in lower overall activation across all models.
* The "Difference" heatmaps highlight the regions where activation is most significantly affected by the "Jailbreak" condition.
* Mistral 7B shows a negative activation band in the "Jailbreak" condition, which is different from the other two models.
### Interpretation
The heatmaps suggest that the "Jailbreak" condition significantly alters the activation patterns within these language models. The strong diagonal activation in the "Benign" condition likely represents the model's normal processing of coherent input. The suppression of activation in the "Jailbreak" condition could indicate that the model is recognizing and attempting to mitigate potentially harmful or undesirable input. The "Difference" heatmaps visually confirm this, showing that the regions of highest activation in the "Benign" condition are most affected by the "Jailbreak" condition.
The negative activation band observed in Mistral 7B during the "Jailbreak" condition is particularly interesting. It could suggest a different mechanism for handling adversarial inputs compared to GPT-J and LLaMA-3. This could be due to architectural differences or training data.
The consistent diagonal pattern across all models and conditions suggests a fundamental aspect of how these models process information, potentially related to attention mechanisms or token relationships. The data suggests that jailbreaking attempts disrupt this normal processing pattern, leading to altered activation landscapes.