\n
## Bar Chart: Speedup Comparison of Language Models
### Overview
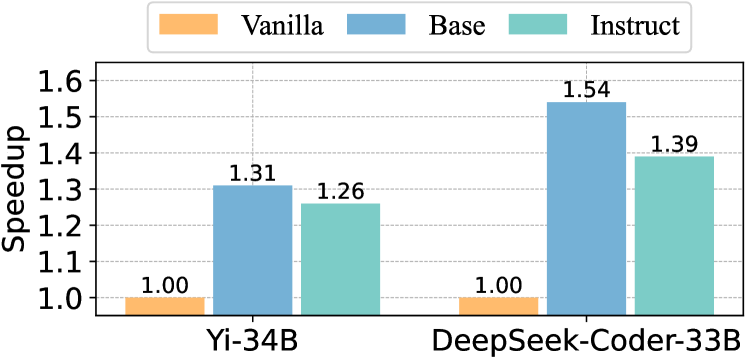
This bar chart compares the speedup achieved by three different training configurations – Vanilla, Base, and Instruct – for two language models: Yi-34B and DeepSeek-Coder-33B. The speedup is measured on the y-axis, while the x-axis represents the language model being evaluated.
### Components/Axes
* **X-axis:** Language Model (Yi-34B, DeepSeek-Coder-33B)
* **Y-axis:** Speedup (Scale ranges from 1.0 to 1.6, with increments of 0.1)
* **Legend:**
* Vanilla (Color: Orange)
* Base (Color: Blue)
* Instruct (Color: Teal)
### Detailed Analysis
The chart consists of six bars, two for each language model, representing the speedup for each training configuration.
**Yi-34B:**
* **Vanilla:** The bar is positioned at approximately 1.00 on the y-axis.
* **Base:** The bar reaches approximately 1.31 on the y-axis. The line slopes upward from the Vanilla bar.
* **Instruct:** The bar reaches approximately 1.26 on the y-axis. The line slopes downward from the Base bar.
**DeepSeek-Coder-33B:**
* **Vanilla:** The bar is positioned at approximately 1.00 on the y-axis.
* **Base:** The bar reaches approximately 1.54 on the y-axis. The line slopes upward from the Vanilla bar.
* **Instruct:** The bar reaches approximately 1.39 on the y-axis. The line slopes downward from the Base bar.
### Key Observations
* The "Base" configuration consistently provides the highest speedup for both language models.
* The "Instruct" configuration provides a speedup that is lower than the "Base" configuration but higher than the "Vanilla" configuration.
* DeepSeek-Coder-33B shows a greater speedup overall compared to Yi-34B, particularly in the "Base" configuration.
* The "Vanilla" configuration has a speedup of 1.00 for both models, indicating no speedup relative to a baseline.
### Interpretation
The data suggests that the "Base" training configuration is the most effective for accelerating both Yi-34B and DeepSeek-Coder-33B. The "Instruct" configuration offers a moderate speedup, while the "Vanilla" configuration provides no speedup. The larger speedup observed with DeepSeek-Coder-33B suggests that this model benefits more from the "Base" training approach than Yi-34B. This could be due to differences in model architecture, training data, or other factors. The consistent pattern of "Base" > "Instruct" > "Vanilla" indicates a clear hierarchy in the effectiveness of these training configurations. The speedup values provide quantitative evidence of the performance gains achieved by each configuration.