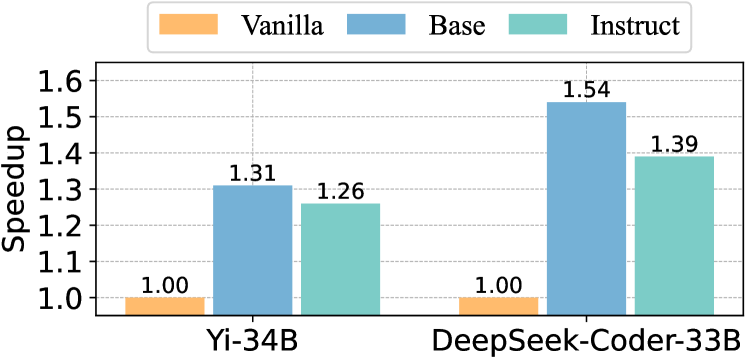
## Grouped Bar Chart: Speedup Comparison of Model Variants
### Overview
This image is a grouped bar chart comparing the "Speedup" metric for two large language models, each with three training variants: Vanilla, Base, and Instruct. The chart visually demonstrates the performance improvement (speedup) of the Base and Instruct variants relative to the Vanilla baseline for each model.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:**
* **Label:** "Speedup"
* **Scale:** Linear scale ranging from 1.0 to 1.6, with major gridlines at intervals of 0.1 (1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6).
* **X-Axis:**
* **Primary Categories (Model Names):** Two distinct groups labeled "Yi-34B" (left group) and "DeepSeek-Coder-33B" (right group).
* **Legend:**
* **Position:** Centered at the top of the chart area.
* **Items:**
1. **Vanilla:** Represented by an orange color.
2. **Base:** Represented by a medium blue color.
3. **Instruct:** Represented by a teal/greenish-blue color.
* **Data Series:** Each model group contains three bars corresponding to the legend items, ordered from left to right as Vanilla, Base, Instruct.
### Detailed Analysis
The chart presents the following specific data points, confirmed by matching bar colors to the legend and reading the numerical labels placed directly above each bar:
**1. Model: Yi-34B (Left Group)**
* **Vanilla (Orange Bar):** Speedup = **1.00**. This is the baseline value.
* **Base (Blue Bar):** Speedup = **1.31**. This bar is the tallest in the Yi-34B group.
* **Instruct (Teal Bar):** Speedup = **1.26**. This bar is shorter than the Base bar but taller than the Vanilla bar.
**2. Model: DeepSeek-Coder-33B (Right Group)**
* **Vanilla (Orange Bar):** Speedup = **1.00**. This is the baseline value, identical to the Yi-34B Vanilla.
* **Base (Blue Bar):** Speedup = **1.54**. This is the tallest bar in the entire chart.
* **Instruct (Teal Bar):** Speedup = **1.39**. This bar is shorter than the DeepSeek-Coder-33B Base bar but taller than its Vanilla bar.
**Trend Verification:**
* For **Yi-34B**, the visual trend is: Base (highest) > Instruct > Vanilla (lowest).
* For **DeepSeek-Coder-33B**, the visual trend is: Base (highest) > Instruct > Vanilla (lowest).
* Comparing across models, both the Base and Instruct variants of DeepSeek-Coder-33B show a higher speedup than their counterparts in Yi-34B.
### Key Observations
1. **Baseline Consistency:** The "Vanilla" variant for both models is set as the baseline with a Speedup value of exactly 1.00.
2. **Performance Hierarchy:** For both models, the "Base" variant achieves the highest speedup, followed by the "Instruct" variant, with "Vanilla" performing the worst.
3. **Model Comparison:** DeepSeek-Coder-33B shows a greater relative improvement from its Base training (1.54 vs. 1.31) and a slightly greater improvement from its Instruct training (1.39 vs. 1.26) compared to Yi-34B.
4. **Magnitude of Improvement:** The most significant single improvement shown is the DeepSeek-Coder-33B Base variant, which is 54% faster than its Vanilla baseline.
### Interpretation
The data suggests that the training methodology significantly impacts inference or processing speedup for these models. The "Base" training approach consistently yields the greatest speedup, indicating it may be the most optimized for raw performance. The "Instruct" variant, while faster than "Vanilla," is slower than "Base," which could imply that adding instruction-following capabilities introduces some computational overhead compared to the base-optimized model.
The fact that DeepSeek-Coder-33B achieves higher speedup values in its optimized variants (Base and Instruct) than Yi-34B could indicate several possibilities: the DeepSeek architecture may be more amenable to these optimization techniques, the training data or process for its variants was more effective for speed, or the baseline "Vanilla" performance of DeepSeek-Coder-33B was different (though both are normalized to 1.00 here). This chart effectively argues that choosing the correct model variant (Base over Instruct or Vanilla) is crucial for maximizing speed, and that the DeepSeek-Coder-33B model, when using its Base variant, offers the highest performance in this specific benchmark.