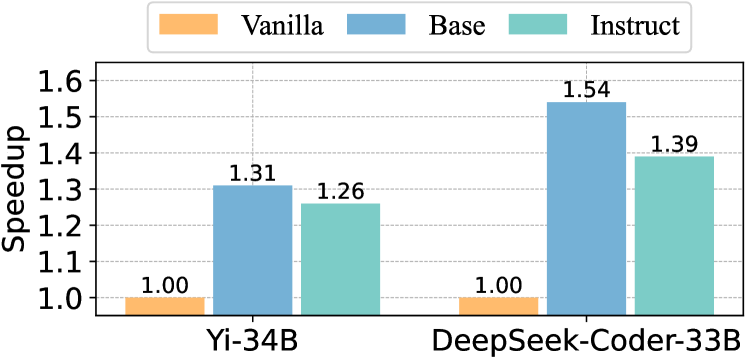
## Bar Chart: Speedup Comparison Across Model Versions
### Overview
The chart compares speedup values (relative to a baseline) for two AI models: Yi-34B and DeepSeek-Coder-33B. Three versions are evaluated: Vanilla, Base, and Instruct. Speedup is measured on a y-axis from 1.00 to 1.6, with each bar representing a version's performance.
### Components/Axes
- **X-axis**: Model names (Yi-34B, DeepSeek-Coder-33B)
- **Y-axis**: Speedup (1.00–1.6, linear scale)
- **Legend**:
- Orange = Vanilla
- Blue = Base
- Teal = Instruct
- **Bar Labels**: Numerical speedup values atop each bar (e.g., "1.31" for Yi-34B Base)
### Detailed Analysis
- **Yi-34B**:
- Vanilla: 1.00 (baseline)
- Base: 1.31 (31% speedup)
- Instruct: 1.26 (26% speedup)
- **DeepSeek-Coder-33B**:
- Vanilla: 1.00 (baseline)
- Base: 1.54 (54% speedup)
- Instruct: 1.39 (39% speedup)
### Key Observations
1. **Base versions dominate**: Both models' Base versions show the highest speedup (1.31 for Yi-34B, 1.54 for DeepSeek-Coder-33B).
2. **Instruct versions underperform Base**: Instruct versions have lower speedup than Base (e.g., Yi-34B Instruct: 1.26 vs. Base: 1.31).
3. **DeepSeek-Coder-33B outperforms Yi-34B**: Its Base version achieves 1.54 speedup, significantly higher than Yi-34B's 1.31.
4. **Vanilla versions are neutral**: All Vanilla versions equal 1.00, serving as the baseline.
### Interpretation
The data suggests that **Base versions are optimized for performance**, achieving substantial speedup over Vanilla and Instruct variants. The **DeepSeek-Coder-33B Base version** is the most efficient, indicating superior architectural or implementation optimizations. The **Instruct versions** likely prioritize instruction-following capabilities over raw speed, resulting in reduced performance. This trade-off highlights a common pattern in model development: specialized variants (e.g., Instruct) may sacrifice speed for task-specific functionality. The Vanilla versions act as a neutral reference, confirming that Base and Instruct versions are meaningfully different.