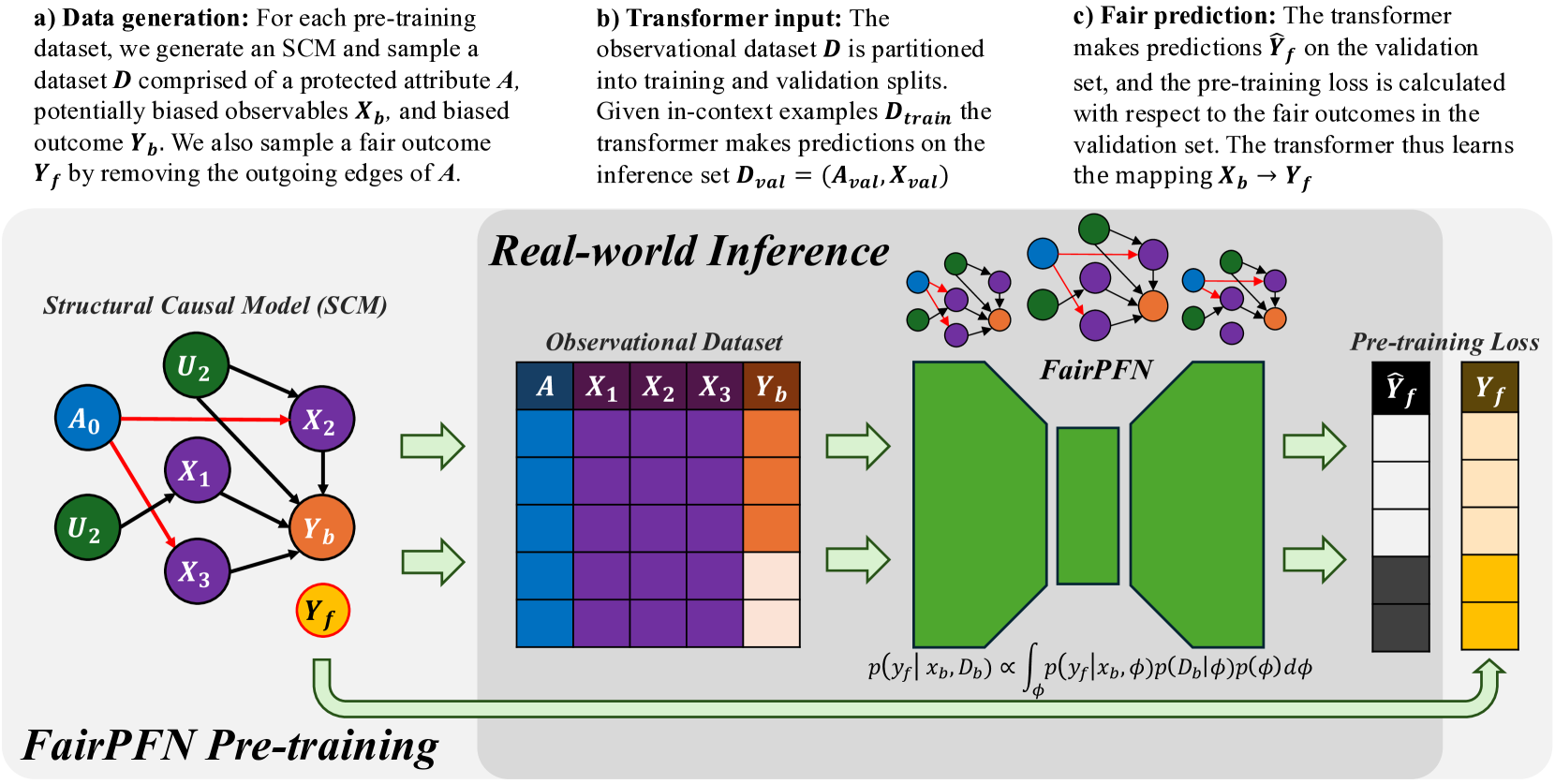
## Data Flow Diagram: FairPFN Pre-training
### Overview
The image is a data flow diagram illustrating the pre-training process of a FairPFN (Fair Prediction Function Network). It shows the generation of data, the input to a transformer, and the fair prediction process. The diagram is divided into three sections: data generation, transformer input, and fair prediction.
### Components/Axes
* **Titles:**
* a) Data generation
* b) Transformer input
* c) Fair prediction
* Structural Causal Model (SCM)
* Real-world Inference
* Observational Dataset
* FairPFN
* Pre-training Loss
* FairPFN Pre-training
* **Variables/Labels:**
* D: Dataset
* A: Protected attribute (blue)
* Xb: Biased observables (purple)
* Yb: Biased outcome (orange)
* Yf: Fair outcome (yellow)
* U2: Unobserved variable (green)
* X1, X2, X3: Observables (purple)
* Dtrain: Training dataset
* Dval: Inference set
* Aval: Protected attribute in inference set
* Xval: Observables in inference set
* Ŷf: Predicted fair outcome (gray scale)
* p(yf|xb, Db): Probability of fair outcome given biased observables and dataset
* φ: Latent variable
* p(yf|xb, φ): Probability of fair outcome given biased observables and latent variable
* p(Db|φ): Probability of dataset given latent variable
* p(φ): Probability of latent variable
* **Diagram Elements:**
* Structural Causal Model (SCM): A directed graph with nodes representing variables and edges representing causal relationships.
* Observational Dataset: A table representing the dataset with columns for A, X1, X2, X3, and Yb.
* FairPFN: A trapezoidal shape representing the Fair Prediction Function Network.
* Pre-training Loss: Two columns representing the predicted fair outcome (Ŷf) and the fair outcome (Yf).
* Arrows: Indicate the flow of data and processes.
### Detailed Analysis or Content Details
**a) Data generation:**
* Text: "For each pre-training dataset, we generate an SCM and sample a dataset D comprised of a protected attribute A, potentially biased observables Xb, and biased outcome Yb. We also sample a fair outcome Yf by removing the outgoing edges of A."
* Structural Causal Model (SCM):
* Nodes: A0 (blue), U2 (green, top), U2 (green, bottom), X1 (purple), X2 (purple), X3 (purple), Yb (orange), Yf (yellow, outlined in red).
* Edges:
* A0 -> X1 (red)
* A0 -> X2 (red)
* A0 -> X3 (red)
* U2 -> X2 (black)
* U2 -> Yb (black)
* X1 -> Yb (black)
* X2 -> Yb (black)
* X3 -> Yb (black)
**b) Transformer input:**
* Text: "The observational dataset D is partitioned into training and validation splits. Given in-context examples Dtrain the transformer makes predictions on the inference set Dval = (Aval, Xval)"
* Observational Dataset:
* Columns: A (blue), X1 (purple), X2 (purple), X3 (purple), Yb (orange).
* Rows: Four rows, each with a different shade of the column color.
**c) Fair prediction:**
* Text: "The transformer makes predictions Ŷf on the validation set, and the pre-training loss is calculated with respect to the fair outcomes in the validation set. The transformer thus learns the mapping Xb -> Yf"
* FairPFN: A green trapezoid.
* Pre-training Loss:
* Ŷf (Predicted fair outcome): Four shades of gray, from black to white.
* Yf (Fair outcome): Four shades of yellow/brown.
* Formula: p(yf|xb, Db) ∝ ∫ p(yf|xb, φ)p(Db|φ)p(φ) dφ
### Key Observations
* The diagram illustrates the process of generating a fair outcome (Yf) from a biased outcome (Yb) using a FairPFN.
* The SCM shows the causal relationships between the variables.
* The observational dataset represents the data used to train the FairPFN.
* The FairPFN makes predictions on the validation set and calculates the pre-training loss.
### Interpretation
The diagram describes a method for mitigating bias in machine learning models. The process starts with a structural causal model that represents the relationships between variables, including a protected attribute (A) and a biased outcome (Yb). The FairPFN is trained to predict a fair outcome (Yf) by learning the mapping from biased observables (Xb) to Yf. The pre-training loss is calculated with respect to the fair outcomes, ensuring that the model learns to predict fair outcomes. The formula represents the probability of the fair outcome given the biased observables and dataset, which is proportional to the integral of the product of the probabilities of the fair outcome given the biased observables and latent variable, the dataset given the latent variable, and the latent variable. This approach aims to remove the influence of the protected attribute on the outcome, resulting in a fairer prediction.