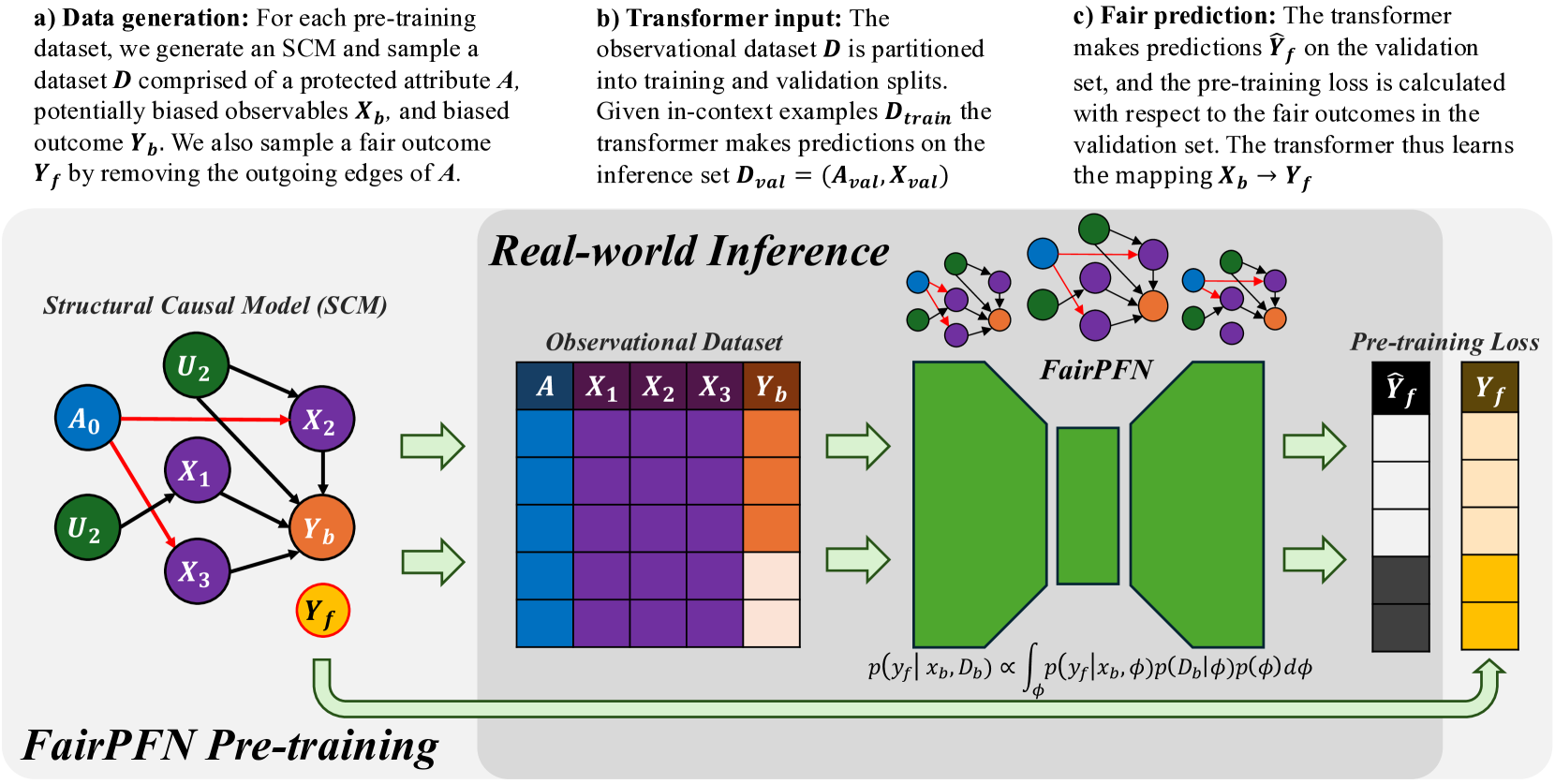
## Diagram: FairPFN Pre-training Process for Fair Prediction
### Overview
The diagram illustrates a technical workflow for training a fair prediction model (FairPFN) using structural causal models (SCM) and observational data. It emphasizes fairness constraints through pre-training loss calculations that compare model predictions against protected attributes and fair outcomes.
### Components/Axes
1. **Structural Causal Model (SCM)**
- Leftmost section with nodes:
- Protected attribute: `A₀` (blue)
- Unobserved confounders: `U₂` (green)
- Observables: `X₁`, `X₂`, `X₃` (purple)
- Biased outcome: `Y_b` (orange)
- Fair outcome: `Y_f` (yellow)
- Arrows indicate causal relationships (e.g., `A₀ → X₂`, `U₂ → X₁`).
2. **Observational Dataset**
- Tabular format with columns:
- `A` (protected attribute, blue)
- `X₁`, `X₂`, `X₃` (observables, purple)
- `Y_b` (biased outcome, orange)
- Color-coded cells suggest data distribution (e.g., darker purple for `X₁`).
3. **FairPFN**
- Central green block representing the model architecture.
- Equations:
- `p(y_f | x_b, D_b) ∝ ∫ p(y_f | x_b, φ)p(D_b | φ)p(φ)dφ`
- Indicates probabilistic inference over fairness parameters (φ).
4. **Pre-training Loss**
- Rightmost section with two columns:
- `Ŷ_f` (model predictions, black bars)
- `Y_f` (fair outcomes, yellow bars)
- Visual comparison of prediction accuracy vs. fairness targets.
### Detailed Analysis
- **SCM to Observational Dataset**:
The SCM generates a dataset `D` with protected attribute `A`, observables `X_b`, and biased outcome `Y_b`. A fair outcome `Y_f` is derived by removing edges from `A`.
- **Transformer Input**:
The observational dataset is split into training (`D_train`) and validation (`D_val`) sets. The transformer maps `X_b → Y_f` using in-context examples.
- **Fair Prediction**:
The transformer makes predictions `Ŷ_f` on the validation set. Pre-training loss is calculated by comparing `Ŷ_f` to `Y_f`, ensuring alignment with fairness constraints.
### Key Observations
1. **Causal Structure**:
- Protected attribute `A₀` influences observables `X_b` via confounders `U₂`, creating potential bias in `Y_b`.
- Fair outcome `Y_f` isolates `X_b` from `A₀` to mitigate bias.
2. **Data Representation**:
- Observational dataset uses color gradients to differentiate data types (e.g., blue for `A`, orange for `Y_b`).
- Pre-training loss bars show a direct comparison between model outputs (`Ŷ_f`) and ground truth (`Y_f`).
3. **Mathematical Formulation**:
- The FairPFN integrates fairness constraints via probabilistic inference over parameters `φ`, balancing prediction accuracy and fairness.
### Interpretation
This workflow demonstrates a fairness-aware machine learning pipeline. By explicitly modeling causal relationships (SCM) and incorporating fairness constraints into the loss function, the model aims to reduce bias in predictions. The pre-training loss acts as a regularization term, penalizing deviations from fair outcomes. The use of observational data with protected attributes highlights challenges in real-world deployment, where unobserved confounders (`U₂`) may still influence fairness. The diagram emphasizes the importance of causal reasoning in designing robust, equitable AI systems.