\n
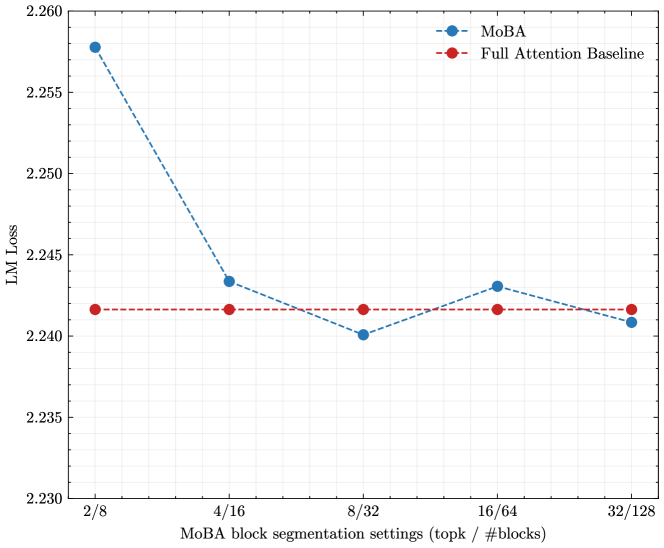
## Line Chart: LM Loss vs. MoBA Block Segmentation Settings
### Overview
This chart displays the Language Model (LM) Loss for two different models, MoBA and a Full Attention Baseline, across varying MoBA block segmentation settings. The x-axis represents the segmentation settings (topk / #blocks), and the y-axis represents the LM Loss. The chart aims to compare the performance of MoBA against a baseline as the block segmentation settings are adjusted.
### Components/Axes
* **X-axis Title:** "MoBA block segmentation settings (topk / #blocks)"
* **X-axis Markers:** 2/8, 4/16, 8/32, 16/64, 32/128
* **Y-axis Title:** "LM Loss"
* **Y-axis Scale:** Ranges from approximately 2.230 to 2.260, with gridlines at 0.005 intervals.
* **Legend:** Located in the top-right corner.
* **MoBA:** Represented by a blue line with circular markers.
* **Full Attention Baseline:** Represented by a red dashed line with circular markers.
### Detailed Analysis
**MoBA (Blue Line):**
The MoBA line starts at a relatively high LM Loss and exhibits a strong downward trend initially.
* At 2/8, the LM Loss is approximately 2.258.
* At 4/16, the LM Loss drops significantly to approximately 2.243.
* At 8/32, the LM Loss continues to decrease slightly to approximately 2.241.
* At 16/64, the LM Loss increases slightly to approximately 2.243.
* At 32/128, the LM Loss decreases slightly to approximately 2.241.
**Full Attention Baseline (Red Dashed Line):**
The Full Attention Baseline line remains relatively stable across all segmentation settings.
* At 2/8, the LM Loss is approximately 2.242.
* At 4/16, the LM Loss is approximately 2.242.
* At 8/32, the LM Loss is approximately 2.241.
* At 16/64, the LM Loss is approximately 2.242.
* At 32/128, the LM Loss is approximately 2.242.
### Key Observations
* MoBA demonstrates a significant reduction in LM Loss as the block segmentation settings increase from 2/8 to 8/32.
* After 8/32, the MoBA line plateaus, with only minor fluctuations in LM Loss.
* The Full Attention Baseline maintains a consistent LM Loss throughout all settings, remaining slightly above the MoBA line after the initial drop.
* The initial performance of MoBA (2/8) is worse than the baseline.
### Interpretation
The data suggests that MoBA benefits from increased block segmentation, up to a point. The initial drop in LM Loss indicates that MoBA is able to more effectively process and learn from the data as the block size increases. However, beyond 8/32, the gains diminish, suggesting that further increasing the block size does not provide significant improvements. The Full Attention Baseline provides a stable performance level, but MoBA ultimately achieves a lower LM Loss after the initial optimization phase. This implies that MoBA, with appropriate block segmentation, can outperform the Full Attention Baseline in terms of language modeling performance. The plateauing of MoBA's performance suggests there may be diminishing returns or other factors limiting further improvement. The initial worse performance of MoBA could be due to the overhead of the block segmentation process, which is overcome as the block size increases and the benefits of the MoBA architecture become more apparent.