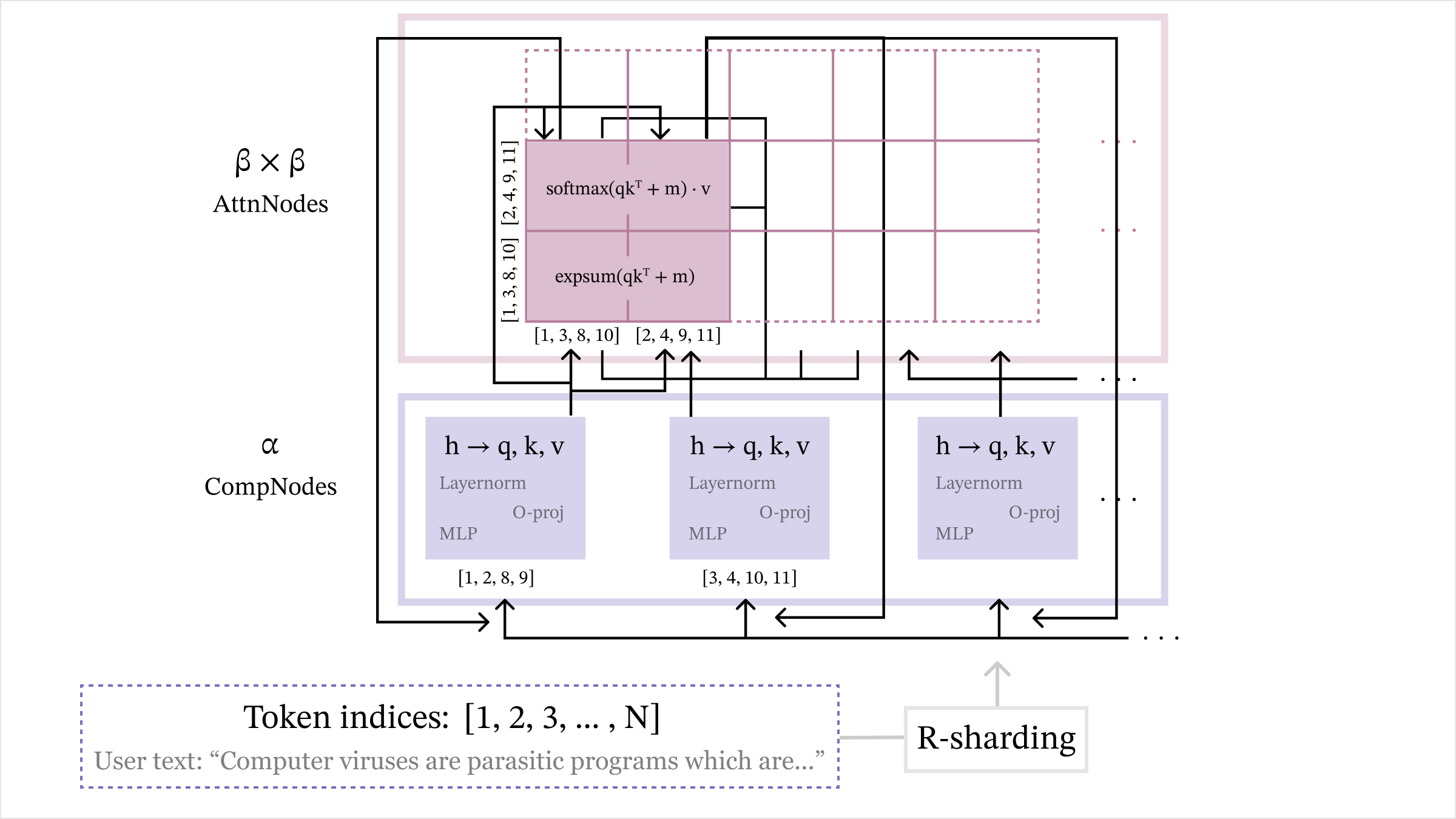
## Diagram: Attention Mechanism with Sharding
### Overview
The image is a diagram illustrating an attention mechanism, likely within a neural network architecture. It shows the flow of data and operations between different components, including token indices, computation nodes (CompNodes), and attention nodes (AttnNodes). The diagram also indicates a sharding operation.
### Components/Axes
* **Title:** None explicitly given, but the diagram depicts an attention mechanism.
* **Labels:**
* "β x β" and "AttnNodes" at the top, indicating the attention nodes and their dimensionality.
* "α" and "CompNodes" in the middle-left, indicating the computation nodes.
* "Token indices: [1, 2, 3, ..., N]" at the bottom, representing the input tokens.
* "User text: 'Computer viruses are parasitic programs which are...'" below the token indices.
* "R-sharding" at the bottom-right.
* Within each CompNode block: "h → q, k, v", "Layernorm", "O-proj", "MLP".
* Within the AttnNodes block: "softmax(qkᵀ + m) . v", "expsum(qkᵀ + m)".
* **Nodes:**
* Three CompNodes, each containing "h → q, k, v", "Layernorm", "O-proj", and "MLP".
* One AttnNodes block containing "softmax(qkᵀ + m) . v" and "expsum(qkᵀ + m)".
* **Connections:** Arrows indicate the flow of data between the components.
* **Index Sets:**
* CompNodes: "[1, 2, 8, 9]", "[3, 4, 10, 11]"
* AttnNodes: "[1, 3, 8, 10]", "[2, 4, 9, 11]"
### Detailed Analysis
1. **Token Indices:** The diagram starts with "Token indices: [1, 2, 3, ..., N]" and a user text snippet: "Computer viruses are parasitic programs which are...". This suggests the input is a sequence of tokens.
2. **CompNodes (Computation Nodes):**
* There are three CompNodes, each performing the same operations:
* "h → q, k, v": This likely represents the transformation of input embeddings (h) into query (q), key (k), and value (v) vectors.
* "Layernorm": Layer normalization.
* "O-proj": Output projection.
* "MLP": Multi-layer perceptron.
* The index sets associated with the first two CompNodes are "[1, 2, 8, 9]" and "[3, 4, 10, 11]". The third CompNode has no explicit index set listed.
3. **AttnNodes (Attention Nodes):**
* The AttnNodes block performs the core attention calculations:
* "softmax(qkᵀ + m) . v": This calculates the attention weights using a softmax function applied to the dot product of query (q) and key (k) plus a mask (m), and then multiplies the result by the value (v).
* "expsum(qkᵀ + m)": This calculates the exponential sum of the dot product of query (q) and key (k) plus a mask (m).
* The index sets associated with the AttnNodes are "[1, 3, 8, 10]" and "[2, 4, 9, 11]".
4. **Data Flow:**
* Arrows indicate the flow of data from the token indices to the CompNodes.
* Arrows also show data flowing from the CompNodes to the AttnNodes.
* There are connections between the AttnNodes and the CompNodes.
5. **Sharding:** "R-sharding" at the bottom-right suggests that the data or computation is being sharded (split) across multiple devices or processors.
### Key Observations
* The diagram illustrates a standard attention mechanism, with query, key, and value vectors being computed and used to calculate attention weights.
* The presence of "Layernorm" and "MLP" indicates that this is likely part of a larger neural network architecture.
* The index sets associated with the nodes suggest that the tokens are being processed in specific groups or shards.
* The "R-sharding" label indicates that the computation is distributed.
### Interpretation
The diagram depicts a sharded attention mechanism within a neural network. The input tokens are processed by computation nodes (CompNodes) to generate query, key, and value vectors. These vectors are then used in the attention nodes (AttnNodes) to calculate attention weights and produce a weighted sum of the value vectors. The sharding operation suggests that the computation is distributed across multiple devices, which is common in large-scale neural network training. The index sets likely represent the specific tokens assigned to each shard. The "softmax(qkᵀ + m) . v" and "expsum(qkᵀ + m)" operations are central to the attention mechanism, allowing the model to focus on the most relevant parts of the input sequence.