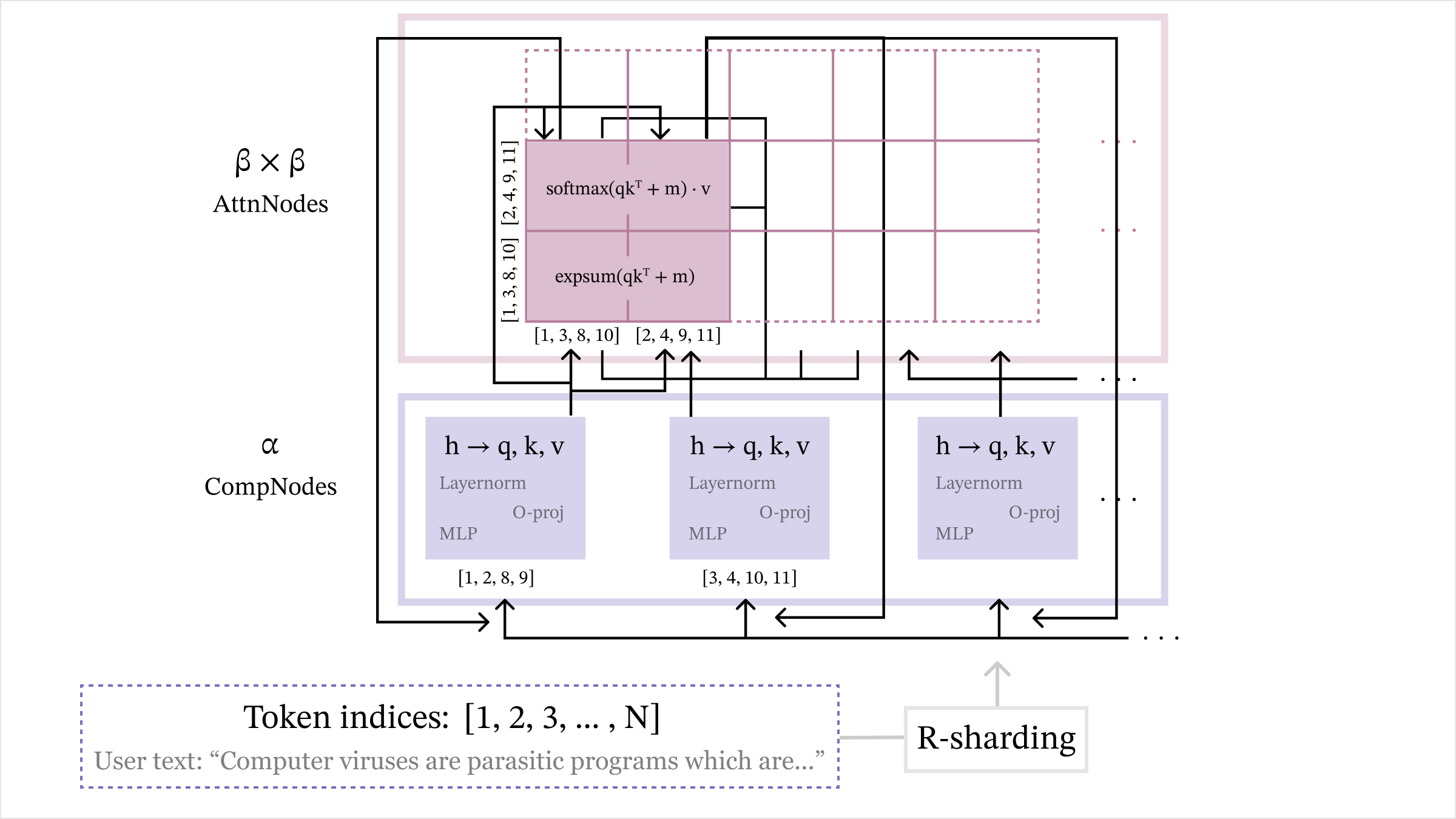
## Transformer Model Architecture Diagram
### Overview
The image depicts a technical diagram of a transformer model architecture, illustrating the flow of data through computational and attention nodes. The diagram includes labeled components, mathematical operations, and token processing steps.
### Components/Axes
1. **CompNodes (α)**:
- Represented as purple rectangles with layered operations
- Contains three parallel processing paths:
- `h → q, k, v` (query, key, value projections)
- Layer normalization
- MLP (Multi-Layer Perceptron)
- O-proj (Output projection)
- Indexed with numerical ranges: [1,2,8,9], [3,4,10,11], etc.
2. **AttnNodes (β×β)**:
- Represented as pink rectangles with attention operations
- Contains:
- `expSum(qkᵀ + m)` (Exponential sum of query-key products)
- `softmax(qkᵀ + m)·v` (Softmax-weighted value aggregation)
- Indexed with numerical ranges: [1,3,8,10], [2,4,9,11], etc.
3. **R-sharding**:
- Positioned at the bottom right
- Indicates distributed computing strategy
4. **Token Indices**:
- Labeled as `[1, 2, 3, ..., N]`
- Contains example user text: "Computer viruses are parasitic programs which are..."
### Detailed Analysis
- **Data Flow**:
1. Token indices enter from the bottom
2. Processed through CompNodes (α) with sequential layer operations
3. Outputs feed into AttnNodes (β×β) for attention computation
4. Results return through R-sharding mechanism
- **Mathematical Operations**:
- `expSum(qkᵀ + m)`: Exponential sum of query-key products with bias
- `softmax(qkᵀ + m)·v`: Softmax-normalized value aggregation
- Layer normalization and MLP operations in CompNodes
### Key Observations
1. The architecture shows parallel processing paths in both CompNodes and AttnNodes
2. Numerical indexing suggests batch processing or sequence positioning
3. R-sharding implies distributed training/inference capabilities
4. The example text demonstrates NLP application context
### Interpretation
This diagram illustrates a transformer architecture optimized for distributed computing (R-sharding) with explicit attention mechanisms. The parallel processing paths in CompNodes suggest efficient computation of embeddings and features, while AttnNodes handle contextual relationships through attention operations. The numerical indexing indicates the model processes sequences in batches, with attention mechanisms operating across different token positions. The example text demonstrates the model's application in natural language processing tasks, particularly in understanding technical content about computer viruses.