## Diagram: Blockwise Decoding vs. Spec-Drafter
### Overview
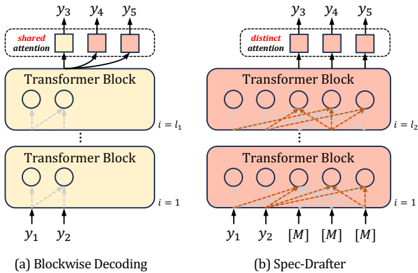
The image presents a comparative diagram illustrating two different decoding approaches: Blockwise Decoding (left) and Spec-Drafter (right). Both approaches utilize Transformer Blocks, but differ in their attention mechanisms and input/output structures.
### Components/Axes
* **Title (Left):** (a) Blockwise Decoding
* **Title (Right):** (b) Spec-Drafter
* **Transformer Block:** Rectangular blocks representing transformer layers.
* **Circles within Transformer Blocks:** Represent internal processing units or nodes.
* **Arrows:** Indicate the flow of information or attention mechanisms.
* **y1, y2, y3, y4, y5:** Output tokens or predictions.
* **[M]:** Represents additional input tokens specific to Spec-Drafter.
* **i = 1:** Denotes the index or layer number of the bottom Transformer Block.
* **i = l1:** Denotes the index or layer number of the top Transformer Block in Blockwise Decoding.
* **i = l2:** Denotes the index or layer number of the top Transformer Block in Spec-Drafter.
* **Shared Attention:** Labeled on the left side, indicating a shared attention mechanism.
* **Distinct Attention:** Labeled on the right side, indicating a distinct attention mechanism.
### Detailed Analysis
**Blockwise Decoding (Left):**
* Two Transformer Blocks are stacked vertically.
* The bottom block is labeled `i = 1`, and the top block is labeled `i = l1`.
* Input tokens `y1` and `y2` are fed into the bottom Transformer Block.
* The bottom Transformer Block has two internal processing units (circles).
* The top Transformer Block also has two internal processing units (circles).
* The output tokens are `y3`, `y4`, and `y5`.
* The "shared attention" mechanism connects the output `y3` to the internal processing units of the top Transformer Block. `y4` and `y5` are connected to `y3`.
**Spec-Drafter (Right):**
* Two Transformer Blocks are stacked vertically.
* The bottom block is labeled `i = 1`, and the top block is labeled `i = l2`.
* Input tokens `y1`, `y2`, and three `[M]` tokens are fed into the bottom Transformer Block.
* The bottom Transformer Block has five internal processing units (circles).
* The top Transformer Block also has five internal processing units (circles).
* The output tokens are `y3`, `y4`, and `y5`.
* The "distinct attention" mechanism connects each output token (`y3`, `y4`, `y5`) to all internal processing units of the top Transformer Block.
### Key Observations
* Blockwise Decoding uses a shared attention mechanism, while Spec-Drafter uses a distinct attention mechanism.
* Spec-Drafter takes additional input tokens `[M]` compared to Blockwise Decoding.
* The number of internal processing units in the Transformer Blocks differs between the two approaches. Blockwise Decoding has 2, while Spec-Drafter has 5.
### Interpretation
The diagram illustrates two different approaches to decoding in a transformer-based model. Blockwise Decoding appears to focus on a more sequential and shared attention mechanism, where the output `y3` influences the generation of `y4` and `y5`. Spec-Drafter, on the other hand, employs a distinct attention mechanism, allowing each output token to attend to all internal processing units independently. The additional input tokens `[M]` in Spec-Drafter likely represent additional context or information used during decoding. The choice between these approaches depends on the specific task and desired properties of the generated output.