\n
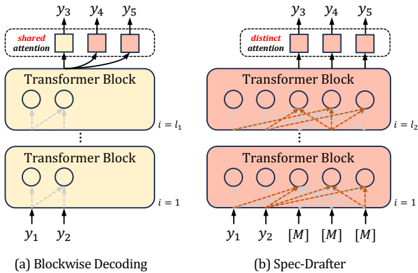
## Diagram: Transformer Block Architectures - Blockwise Decoding vs. Spec-Drafter
### Overview
The image presents a comparative diagram illustrating two different architectures for transformer blocks used in decoding processes: "Blockwise Decoding" (left) and "Spec-Drafter" (right). Both architectures involve stacked transformer blocks, but differ in how attention is handled between layers and how outputs are generated. The diagram focuses on the flow of information and attention mechanisms within these architectures.
### Components/Axes
The diagram consists of two main sections, labeled (a) and (b), representing the two architectures. Each section contains stacked "Transformer Block" components.
- **Labels:** "shared attention" (top-left), "distinct attention" (top-right), "i = l₁" (middle-left), "i = l₂" (middle-right), "i = 1" (bottom-left and bottom-right), "y₁", "y₂", "y₃", "y₄", "y₅" (outputs), "[M]" (placeholder output).
- **Components:** Transformer Blocks (represented as rectangles with circles inside), Attention connections (represented as curved arrows).
- **Text:** "(a) Blockwise Decoding", "(b) Spec-Drafter".
### Detailed Analysis or Content Details
**Section (a) - Blockwise Decoding:**
* The architecture consists of two stacked Transformer Blocks. The bottom block receives inputs "y₁" and "y₂".
* The top block receives outputs "y₃", "y₄", and "y₅".
* Attention connections are shown as curved arrows. The top block has a "shared attention" mechanism, indicated by a square box connecting the attention paths. This suggests that the attention weights are shared across the outputs "y₃", "y₄", and "y₅".
* The vertical dashed line labeled "i = l₁" and "i = 1" indicate the layer index.
**Section (b) - Spec-Drafter:**
* This architecture also consists of two stacked Transformer Blocks. The bottom block receives inputs "y₁", "y₂", and multiple "[M]" placeholders.
* The top block receives outputs "y₃", "y₄", and "y₅".
* Attention connections are shown as curved arrows. The top block has a "distinct attention" mechanism, indicated by a square box. This suggests that each output "y₃", "y₄", and "y₅" has its own dedicated attention weights.
* The vertical dashed line labeled "i = l₂" and "i = 1" indicate the layer index.
* The "[M]" placeholders suggest that the Spec-Drafter architecture can handle variable-length inputs or outputs.
### Key Observations
* The primary difference between the two architectures lies in the attention mechanism. Blockwise Decoding uses shared attention, while Spec-Drafter uses distinct attention.
* Spec-Drafter appears to be more flexible, as indicated by the "[M]" placeholders, potentially allowing it to handle variable-length sequences.
* Both architectures use stacked Transformer Blocks, suggesting a similar underlying structure.
### Interpretation
The diagram illustrates two different approaches to decoding in transformer models. Blockwise Decoding simplifies the attention mechanism by sharing weights across outputs, potentially reducing computational cost but also limiting expressiveness. Spec-Drafter, on the other hand, uses distinct attention for each output, allowing for more nuanced attention patterns but potentially increasing computational complexity. The "[M]" placeholders in Spec-Drafter suggest a mechanism for handling variable-length sequences, which could be useful in tasks like machine translation or speech recognition. The choice between these architectures likely depends on the specific application and the trade-off between computational cost and performance. The diagram highlights a design decision in transformer architecture, focusing on the attention mechanism and its impact on model flexibility and efficiency. The use of dashed lines to indicate layer indices suggests a multi-layered approach to the transformer blocks.