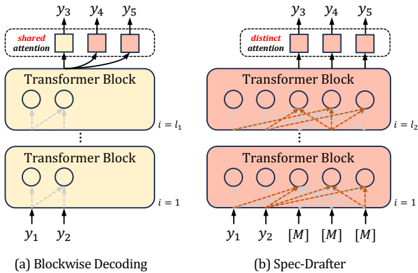
## Diagram: Comparison of Blockwise Decoding and Spec-Drafter Architectures
### Overview
The image is a technical diagram comparing two sequence generation or decoding architectures, likely for autoregressive models like Transformers. It visually contrasts a standard "Blockwise Decoding" method with a proposed "Spec-Drafter" method, highlighting differences in attention mechanisms and input processing.
### Components/Axes
The diagram is split into two main vertical panels:
* **Left Panel (a):** Labeled "(a) Blockwise Decoding". It has a yellow color scheme.
* **Right Panel (b):** Labeled "(b) Spec-Drafter". It has a pink/salmon color scheme.
**Common Components in Both Panels:**
* **Transformer Blocks:** Rectangular boxes representing layers of a Transformer model. They are stacked vertically.
* **Inputs:** Arrows pointing upward into the bottom of the Transformer Blocks, labeled `y₁` and `y₂`.
* **Outputs:** Arrows pointing upward from the top of the Transformer Blocks, labeled `y₃`, `y₄`, and `y₅`.
* **Attention Mechanism:** A dashed box at the top of each panel containing smaller squares representing attention heads or operations.
* **Layer Index:** Text on the right side of the Transformer Blocks indicating the layer number, using the notation `i = 1` for the bottom block and `i = l₁` or `i = l₂` for the top block.
**Specific Labels & Text:**
* **Panel (a) - Blockwise Decoding:**
* Inside the top dashed box: The text **"shared attention"**.
* The two Transformer Blocks are identical in color (yellow).
* Dotted gray arrows connect the input `y₁` and `y₂` to the internal circles (representing tokens or positions) within the blocks, showing a standard causal (left-to-right) flow.
* **Panel (b) - Spec-Drafter:**
* Inside the top dashed box: The text **"distinct attention"**.
* The two Transformer Blocks are identical in color (pink).
* In addition to inputs `y₁` and `y₂`, there are three additional inputs labeled **`[M]`**. These are likely "mask" or "draft" tokens.
* Solid orange arrows show a more complex connectivity pattern. Inputs `y₁` and `y₂` connect to multiple positions in the lower block. The `[M]` tokens also connect to multiple positions. The outputs of the lower block feed into the upper block with a dense, cross-connected pattern (orange arrows).
### Detailed Analysis
**1. Blockwise Decoding (Panel a):**
* **Flow:** Processes two initial tokens (`y₁`, `y₂`) through stacked Transformer blocks (`i=1` to `i=l₁`).
* **Attention:** Uses a **"shared attention"** mechanism across the output positions for `y₃`, `y₄`, `y₅`. This suggests the same attention pattern or parameters are used to generate all subsequent tokens in the block.
* **Connectivity:** The internal dotted lines suggest a standard autoregressive mask where each token can only attend to previous tokens.
**2. Spec-Drafter (Panel b):**
* **Flow:** Processes the same two initial tokens (`y₁`, `y₂`) plus three special `[M]` tokens through stacked Transformer blocks (`i=1` to `i=l₂`).
* **Attention:** Uses a **"distinct attention"** mechanism. This implies that the attention pattern or parameters may differ for each output position (`y₃`, `y₄`, `y₅`), potentially allowing for more flexible or parallelized generation.
* **Connectivity:** The solid orange arrows indicate a much denser connection scheme. The initial tokens and `[M]` tokens appear to attend to each other and to multiple positions within the block in a non-strictly-causal manner. This is characteristic of speculative decoding or drafting architectures, where multiple candidate tokens (`[M]`) are processed in parallel to propose future sequences.
### Key Observations
1. **Architectural Divergence:** The core difference lies in the attention mechanism ("shared" vs. "distinct") and the input set (standard tokens vs. standard tokens plus `[M]` draft tokens).
2. **Increased Parallelism in Spec-Drafter:** The dense, cross-connected orange arrows in panel (b) suggest that the Spec-Drafter architecture enables significantly more parallel computation within a single forward pass compared to the more sequential, blockwise approach in panel (a).
3. **Purpose of `[M]` Tokens:** The `[M]` tokens are a key differentiator. They are likely placeholders for speculative or draft tokens that allow the model to predict multiple future steps (`y₃`, `y₄`, `y₅`) simultaneously, which can then be verified.
4. **Layer Count:** The diagram uses `l₁` and `l₂` for the top layer indices, which may imply the two methods could use a different number of Transformer blocks, though this is not explicitly stated.
### Interpretation
This diagram illustrates a method to accelerate autoregressive text (or sequence) generation. **Blockwise Decoding (a)** represents a conventional approach where tokens are generated in a fixed-size block, but the attention for generating the entire block is "shared," which may be a simplification or a specific efficient implementation.
**Spec-Drafter (b)** proposes an enhancement. By introducing special `[M]` (mask/draft) tokens and employing "distinct attention," the architecture can process multiple potential future tokens in parallel within the same model forward pass. The complex web of connections (orange arrows) shows that these draft tokens and the real context tokens (`y₁`, `y₂`) interact extensively, allowing the model to draft a sequence of candidates (`y₃`, `y₄`, `y₅`) more efficiently. This is a visual representation of the core principle behind **speculative decoding**: using a faster, less accurate "drafter" (which could be this Spec-Drafter module) to propose multiple tokens, which are then verified by a larger model, thereby reducing the total number of serial decoding steps required. The "distinct attention" is crucial for allowing each draft position to have a tailored view of the context.