## Diagram: Transformer Block Architectures for Blockwise Decoding and Spec-Drafter
### Overview
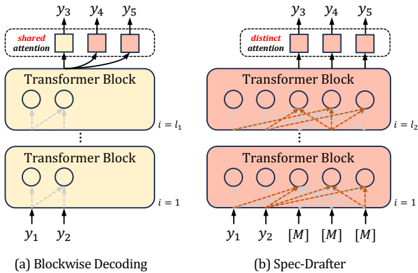
The image compares two Transformer-based architectures: **(a) Blockwise Decoding** and **(b) Spec-Drafter**. Both use Transformer Blocks but differ in attention mechanisms and input/output configurations. The diagrams emphasize attention flow (solid vs. dashed lines) and positional relationships between nodes.
---
### Components/Axes
1. **Transformer Blocks**:
- **Blockwise Decoding (a)**:
- Two stacked Transformer Blocks.
- **Block 1 (i=1)**: Input nodes `y1`, `y2` (circles).
- **Block 2 (i=l₁)**: Output nodes `y3`, `y4`, `y5` (circles).
- **Shared Attention**: Red-highlighted connections between Block 1 and Block 2.
- **Spec-Drafter (b)**:
- Two stacked Transformer Blocks.
- **Block 1 (i=1)**: Input nodes `y1`, `y2` (circles).
- **Block 2 (i=l₂)**: Output nodes `y3`, `y4`, `y5`, and three `[M]` placeholders (circles).
- **Distinct Attention**: Orange dashed lines connecting Block 1 to all nodes in Block 2.
2. **Attention Mechanisms**:
- **Shared Attention (a)**: Arrows from `y1`/`y2` to `y3`/`y4`/`y5` (solid lines).
- **Distinct Attention (b)**: Arrows from `y1`/`y2` to all nodes in Block 2 (dashed lines).
3. **Notation**:
- `[M]`: Placeholder nodes in Spec-Drafter (b), likely representing masked or missing data.
---
### Detailed Analysis
- **Blockwise Decoding (a)**:
- Sequential processing: Inputs `y1`/`y2` are processed in Block 1, then outputs are fed to Block 2.
- Shared attention implies outputs from Block 1 influence all nodes in Block 2.
- No masking; all nodes in Block 2 are active.
- **Spec-Drafter (b)**:
- Inputs `y1`/`y2` attend to all nodes in Block 2, including `[M]` placeholders.
- Distinct attention allows selective focus on specific nodes (e.g., `y3`/`y4`/`y5` vs. `[M]`).
- `[M]` nodes may represent:
- Unprocessed positions (e.g., future tokens in a sequence).
- Ignored or irrelevant positions (e.g., padding).
---
### Key Observations
1. **Attention Scope**:
- Blockwise Decoding uses **shared attention** across blocks, limiting cross-block flexibility.
- Spec-Drafter uses **distinct attention**, enabling dynamic focus on masked/unmasked nodes.
2. **Node Configuration**:
- Blockwise Decoding has fewer nodes (3 outputs in Block 2).
- Spec-Drafter includes `[M]` placeholders, suggesting variable-length or incomplete sequences.
3. **Flow Direction**:
- Both diagrams show bottom-to-top processing (inputs at the bottom, outputs at the top).
---
### Interpretation
- **Blockwise Decoding (a)**:
- Likely used for fixed-length sequences where outputs from earlier blocks directly influence later blocks.
- Shared attention may reduce computational complexity but limit adaptability.
- **Spec-Drafter (b)**:
- Designed for variable-length or incomplete sequences (e.g., autoregressive generation with masking).
- Distinct attention allows the model to prioritize relevant nodes (e.g., `y3`/`y4`/`y5`) while ignoring `[M]` placeholders.
- The `[M]` nodes could represent:
- **Future tokens** in a sequence (e.g., during autoregressive decoding).
- **Padding** for alignment in batch processing.
- **Technical Implications**:
- Blockwise Decoding prioritizes efficiency via shared attention.
- Spec-Drafter emphasizes flexibility via distinct attention and masking, critical for tasks like text generation or handling irregular data.
---
### Missing Data/Uncertainties
- No numerical values or quantitative metrics are provided (e.g., attention weights, performance metrics).
- The exact role of `[M]` placeholders (e.g., masking strategy, positional encoding) is not explicitly defined.
- The diagrams focus on structural differences rather than empirical results.