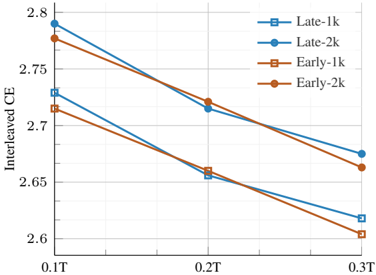
## Line Graph: Interleaved CE Trends Across Time Points and Categories
### Overview
The image depicts a line graph comparing "Interleaved CE" values across three time points (0.1T, 0.2T, 0.3T) for four distinct categories: Late-1k, Late-2k, Early-1k, and Early-2k. The graph uses color-coded lines with unique markers to differentiate categories, showing trends in CE values as time progresses.
### Components/Axes
- **Y-Axis**: Labeled "Interleaved CE," scaled from 2.6 to 2.8 in increments of 0.05.
- **X-Axis**: Labeled with time points: 0.1T, 0.2T, 0.3T.
- **Legend**: Positioned in the top-right corner, with four entries:
- **Late-1k**: Blue line with square markers.
- **Late-2k**: Blue line with circular markers.
- **Early-1k**: Orange line with square markers.
- **Early-2k**: Orange line with circular markers.
### Detailed Analysis
1. **Late-1k (Blue Squares)**:
- Starts at ~2.78 at 0.1T.
- Decreases to ~2.72 at 0.2T.
- Further drops to ~2.66 at 0.3T.
- **Trend**: Steady decline.
2. **Late-2k (Blue Circles)**:
- Begins at ~2.76 at 0.1T.
- Falls to ~2.70 at 0.2T.
- Reaches ~2.64 at 0.3T.
- **Trend**: Consistent downward slope.
3. **Early-1k (Orange Squares)**:
- Starts at ~2.77 at 0.1T.
- Drops to ~2.68 at 0.2T.
- Ends at ~2.62 at 0.3T.
- **Trend**: Sharp decline, steeper than Late-1k.
4. **Early-2k (Orange Circles)**:
- Begins at ~2.75 at 0.1T.
- Decreases to ~2.66 at 0.2T.
- Reaches ~2.60 at 0.3T.
- **Trend**: Gradual but steady reduction.
### Key Observations
- All categories show a **decreasing trend** in Interleaved CE as time progresses from 0.1T to 0.3T.
- **Early categories** (1k and 2k) consistently start with higher CE values than their Late counterparts but end lower by 0.3T.
- **Crossing lines**: Early-1k and Late-2k intersect near 0.2T, suggesting a temporary overlap in CE values.
- **Largest gap**: At 0.1T, Early-1k (2.77) exceeds Late-2k (2.76) by 0.01. By 0.3T, Early-2k (2.60) is 0.06 below Late-1k (2.66).
### Interpretation
The data suggests that **timing (Early vs. Late)** and **category magnitude (1k vs. 2k)** influence Interleaved CE values. Early categories initially outperform Late ones but degrade more rapidly over time, potentially indicating a trade-off between early performance and long-term stability. The steeper decline in Early-1k compared to Early-2k implies that higher magnitude (1k vs. 2k) exacerbates the rate of CE reduction. The crossing lines at 0.2T highlight a critical inflection point where Early and Late categories converge, possibly reflecting a system transition or external factor altering the trend. This could inform optimization strategies for balancing early gains with sustained performance.