\n
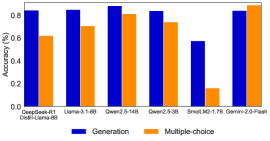
## Bar Chart: Model Accuracy Comparison
### Overview
This bar chart compares the accuracy of several language models on two different tasks: "Generation" and "Multiple-choice". The accuracy is measured as a percentage, ranging from 0% to 1%. The chart displays the accuracy for each model and task using adjacent bars.
### Components/Axes
* **X-axis:** Model Names - DeepSeek-R1, Llama-3.1-6B, Qwen-2.5-14B, Qwen-2.5-3B, SmalLM2-1.7B, Gemini-2.0-Flash. Below each model name, a secondary label is present: "Dweel-Llama-8B" appears under DeepSeek-R1.
* **Y-axis:** Accuracy (%) - Scale ranges from 0.0 to 1.0, with increments of 0.2.
* **Legend:**
* Blue: Generation
* Orange: Multiple-choice
* **Chart Title:** Not explicitly present.
### Detailed Analysis
The chart consists of six sets of paired bars, one for each model. The blue bar represents the "Generation" accuracy, and the orange bar represents the "Multiple-choice" accuracy.
* **DeepSeek-R1:** Generation accuracy is approximately 0.72. Multiple-choice accuracy is approximately 0.64.
* **Llama-3.1-6B:** Generation accuracy is approximately 0.84. Multiple-choice accuracy is approximately 0.72.
* **Qwen-2.5-14B:** Generation accuracy is approximately 0.88. Multiple-choice accuracy is approximately 0.82.
* **Qwen-2.5-3B:** Generation accuracy is approximately 0.77. Multiple-choice accuracy is approximately 0.70.
* **SmalLM2-1.7B:** Generation accuracy is approximately 0.72. Multiple-choice accuracy is approximately 0.16.
* **Gemini-2.0-Flash:** Generation accuracy is approximately 0.86. Multiple-choice accuracy is approximately 0.78.
The Generation bars generally trend upwards, with Qwen-2.5-14B showing the highest accuracy. The Multiple-choice bars show more variability.
### Key Observations
* Qwen-2.5-14B consistently demonstrates the highest accuracy in both Generation and Multiple-choice tasks.
* SmalLM2-1.7B exhibits a significant disparity between Generation and Multiple-choice accuracy, with very low performance on the Multiple-choice task.
* The Generation task generally yields higher accuracy scores compared to the Multiple-choice task across all models.
* The secondary label "Dweel-Llama-8B" under DeepSeek-R1 suggests a potential relationship or comparison between these two models.
### Interpretation
The data suggests that the Qwen-2.5-14B model is the most accurate among those tested, performing well on both Generation and Multiple-choice tasks. The large difference in performance for SmalLM2-1.7B on the Multiple-choice task could indicate a weakness in its ability to select the correct answer from a given set of options, while it performs comparably on generating text. The consistently higher accuracy scores for the Generation task across all models might indicate that these models are generally better at creating text than at evaluating pre-defined options. The presence of "Dweel-Llama-8B" under DeepSeek-R1 could be a reference to a fine-tuned version or a related model used in the evaluation process. Further investigation would be needed to understand the exact relationship. The chart provides a comparative performance overview of these language models, which can be valuable for selecting the most appropriate model for specific natural language processing applications.