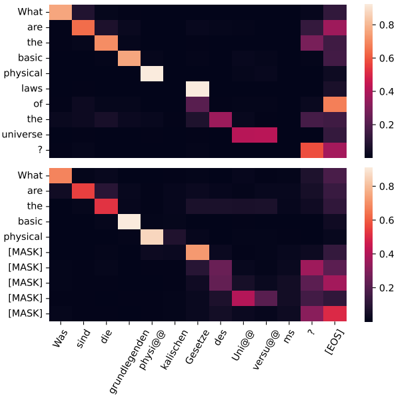
## Heatmap: Comparative Analysis of Textual Elements
### Overview
The image contains two vertically stacked heatmaps, each representing a grid of colored squares. The top heatmap uses English labels, while the bottom heatmap uses German labels. Both heatmaps share a color scale legend on the right, indicating values from 0.2 (dark purple) to 0.8 (bright yellow). The heatmaps likely represent some form of similarity, correlation, or frequency distribution between textual elements.
---
### Components/Axes
#### Top Heatmap (English Labels)
- **X-axis labels**:
- "What are"
- "the"
- "basic"
- "physical"
- "laws"
- "of"
- "the"
- "universe"
- "?"
- **Y-axis labels**:
- "What are"
- "the"
- "basic"
- "physical"
- "laws"
- "of"
- "the"
- "universe"
- "?"
- **Legend**:
- Color scale: Dark purple (0.2) to bright yellow (0.8).
#### Bottom Heatmap (German Labels)
- **X-axis labels**:
- "Was sind"
- "die"
- "grundlegenden"
- "physikalischen"
- "Gesetze"
- "des"
- "Universums"
- "?"
- **Y-axis labels**:
- "Was sind"
- "die"
- "grundlegenden"
- "physikalischen"
- "Gesetze"
- "des"
- "Universums"
- "?"
- **Legend**:
- Same color scale as the top heatmap (0.2–0.8).
---
### Detailed Analysis
#### Top Heatmap (English)
- **Grid structure**: 9x9 grid of colored squares.
- **Color distribution**:
- **Top-left corner**: Light yellow (≈0.8) for "What are" vs "What are".
- **Diagonal trend**: Lighter colors (higher values) along the diagonal from top-left to bottom-right.
- **Off-diagonal**: Darker colors (lower values) in the lower-right quadrant.
- **Notable**: The square for "laws" vs "laws" is bright yellow (≈0.8), while "universe" vs "universe" is dark purple (≈0.2).
#### Bottom Heatmap (German)
- **Grid structure**: 9x9 grid of colored squares.
- **Color distribution**:
- **Top-left corner**: Orange (≈0.6) for "Was sind" vs "Was sind".
- **Diagonal trend**: Lighter colors (higher values) along the diagonal, but less intense than the English heatmap.
- **Off-diagonal**: Darker colors (lower values) in the lower-right quadrant.
- **Notable**: The square for "Gesetze" vs "Gesetze" is bright red (≈0.4), while "Universums" vs "Universums" is dark purple (≈0.2).
---
### Key Observations
1. **Diagonal dominance**: Both heatmaps show higher values (lighter colors) along the diagonal, suggesting self-similarity or strong correlation between identical terms.
2. **Language differences**: The German heatmap has slightly lower maximum values (e.g., "Was sind" vs "Was sind" ≈0.6 vs English "What are" vs "What are" ≈0.8).
3. **Term-specific patterns**:
- "Laws" (English) and "Gesetze" (German) show moderate to high values (≈0.4–0.6).
- "Universe" (English) and "Universums" (German) show low values (≈0.2).
4. **Color consistency**: The legend confirms that darker colors correspond to lower values, and lighter colors to higher values.
---
### Interpretation
The heatmaps likely represent a **similarity or frequency matrix** between textual elements, possibly from a natural language processing (NLP) task. The diagonal dominance indicates that identical terms (e.g., "What are" vs "What are") are strongly correlated, while off-diagonal terms (e.g., "What are" vs "the") have lower values. The German heatmap’s lower maximum values suggest differences in how terms are represented or weighted in the two languages. The "laws" and "Gesetze" terms show moderate similarity, while "universe" and "Universums" are less correlated. This could reflect linguistic nuances or differences in how concepts are encoded in different languages.
The heatmaps may be used to analyze **cross-lingual semantic similarity**, **keyword frequency**, or **textual alignment** in multilingual datasets. The absence of explicit numerical values in the image necessitates reliance on the color scale for approximate interpretations.