## Line Chart: Scaling verifier compute: ProcessBench
### Overview
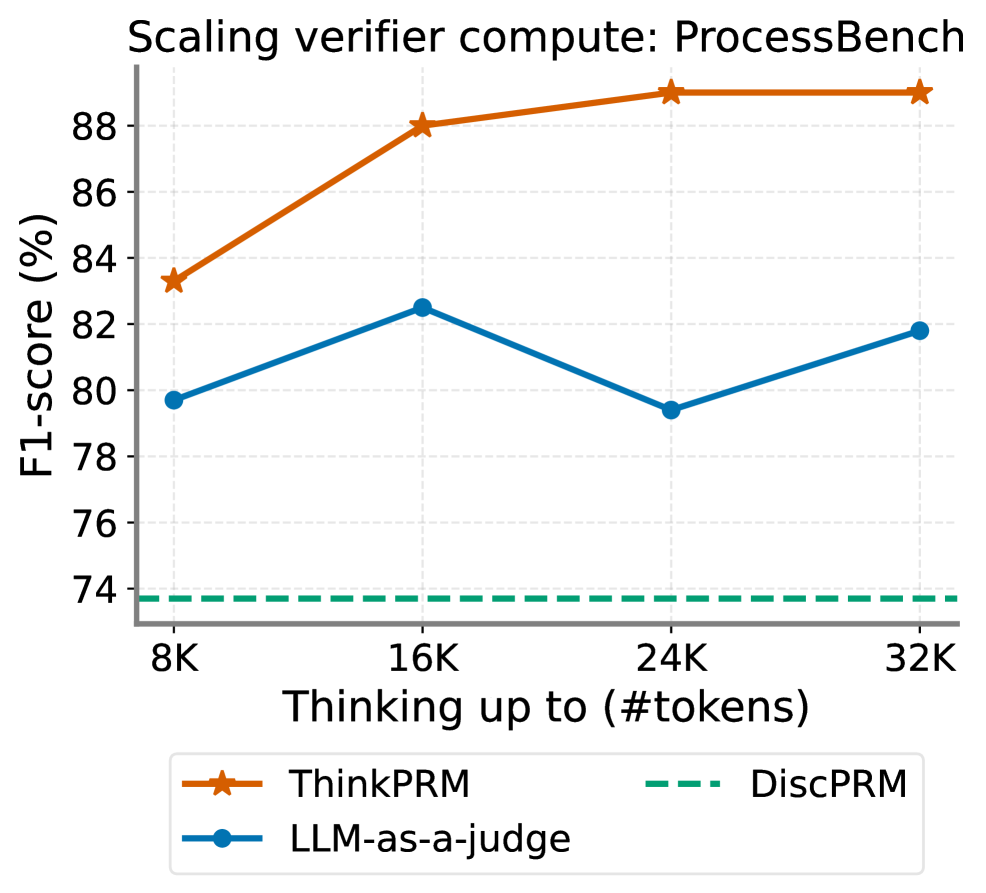
The image is a line chart comparing the F1-score (%) of three different methods (ThinkPRM, LLM-as-a-judge, and DiscPRM) as the "Thinking up to (#tokens)" increases. The x-axis represents the number of tokens, ranging from 8K to 32K. The y-axis represents the F1-score in percentage, ranging from 74% to 90%.
### Components/Axes
* **Title:** Scaling verifier compute: ProcessBench
* **X-axis Title:** Thinking up to (#tokens)
* **X-axis Markers:** 8K, 16K, 24K, 32K
* **Y-axis Title:** F1-score (%)
* **Y-axis Markers:** 74, 76, 78, 80, 82, 84, 86, 88
* **Legend:** Located at the bottom of the chart.
* ThinkPRM (orange line with star markers)
* LLM-as-a-judge (blue line with circle markers)
* DiscPRM (dashed green line)
### Detailed Analysis
* **ThinkPRM (orange line with star markers):** The F1-score increases from approximately 83% at 8K tokens to approximately 88% at 16K tokens. It then plateaus around 89% at 24K and 32K tokens.
* 8K: ~83%
* 16K: ~88%
* 24K: ~89%
* 32K: ~89%
* **LLM-as-a-judge (blue line with circle markers):** The F1-score increases from approximately 79.5% at 8K tokens to approximately 82.5% at 16K tokens. It then decreases to approximately 79.5% at 24K tokens before increasing again to approximately 81.5% at 32K tokens.
* 8K: ~79.5%
* 16K: ~82.5%
* 24K: ~79.5%
* 32K: ~81.5%
* **DiscPRM (dashed green line):** The F1-score remains constant at approximately 73.5% across all token values.
### Key Observations
* ThinkPRM consistently outperforms LLM-as-a-judge and DiscPRM across all token values.
* The performance of ThinkPRM plateaus after 16K tokens.
* The performance of DiscPRM remains constant regardless of the number of tokens.
* LLM-as-a-judge shows a slight increase in F1-score from 8K to 16K tokens, then a decrease at 24K, followed by a slight increase at 32K.
### Interpretation
The chart demonstrates the scaling performance of three different methods for a "verifier compute" task on "ProcessBench." ThinkPRM shows the best performance and scales well up to 16K tokens, after which its performance plateaus. LLM-as-a-judge shows a more variable performance with a peak at 16K tokens. DiscPRM's performance is consistently low and unaffected by the number of tokens, suggesting it may not be suitable for this task or requires further optimization. The data suggests that increasing the number of tokens beyond 16K may not significantly improve the performance of ThinkPRM, while LLM-as-a-judge's performance fluctuates.