\n
## Line Chart: Scaling verifier compute: ProcessBench
### Overview
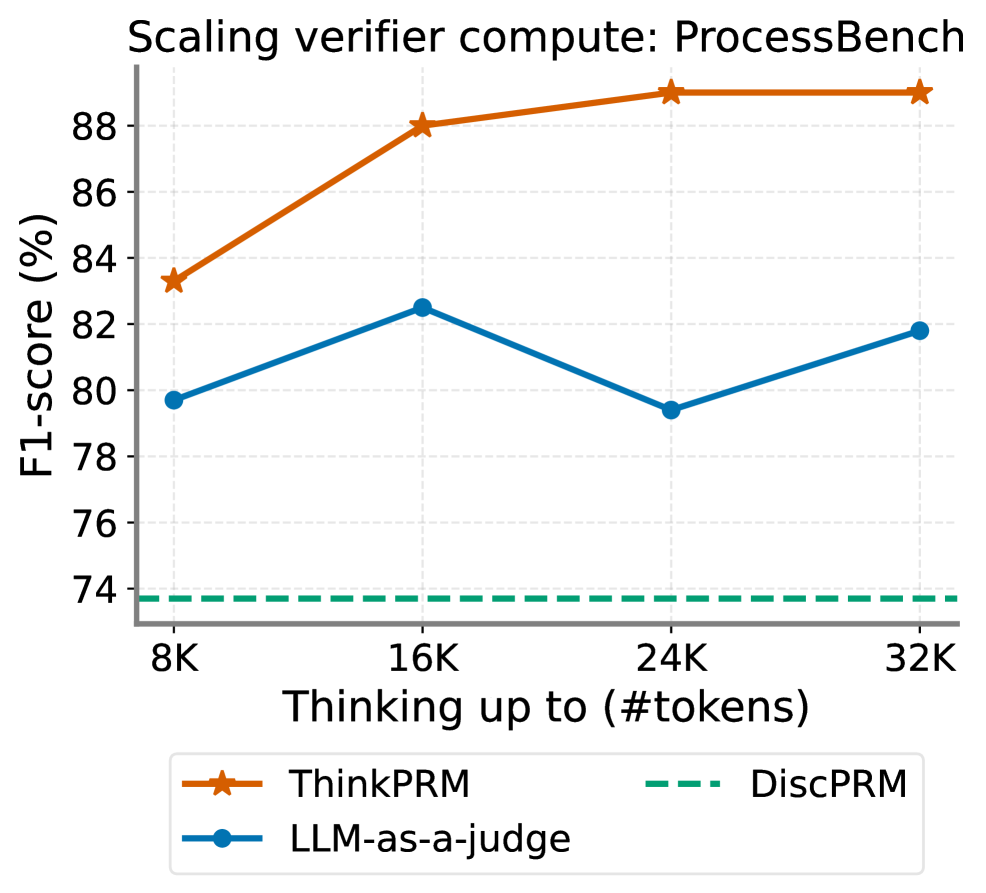
This line chart illustrates the performance of different verification methods (ThinkPRM, DiscPRM, and LLM-as-a-judge) on the ProcessBench dataset as a function of the number of tokens used for "thinking" (up to 32K tokens). The performance metric is F1-score, expressed as a percentage.
### Components/Axes
* **Title:** Scaling verifier compute: ProcessBench
* **X-axis:** Thinking up to (#tokens) - with markers at 8K, 16K, 24K, and 32K.
* **Y-axis:** F1-score (%) - ranging from approximately 74% to 89%. The axis has tick marks at 76%, 78%, 80%, 82%, 84%, 86%, 88%.
* **Legend:** Located at the bottom of the chart.
* ThinkPRM (Orange line with star markers)
* DiscPRM (Teal dashed line)
* LLM-as-a-judge (Blue line with circle markers)
### Detailed Analysis
* **ThinkPRM (Orange):** The line slopes upward from 8K to 16K tokens, then plateaus.
* 8K tokens: Approximately 84% F1-score.
* 16K tokens: Approximately 88% F1-score.
* 24K tokens: Approximately 89% F1-score.
* 32K tokens: Approximately 89% F1-score.
* **DiscPRM (Teal):** The line is nearly flat across all token values.
* 8K tokens: Approximately 74% F1-score.
* 16K tokens: Approximately 74% F1-score.
* 24K tokens: Approximately 74% F1-score.
* 32K tokens: Approximately 74% F1-score.
* **LLM-as-a-judge (Blue):** The line shows a slight downward trend.
* 8K tokens: Approximately 80% F1-score.
* 16K tokens: Approximately 82% F1-score.
* 24K tokens: Approximately 80% F1-score.
* 32K tokens: Approximately 79% F1-score.
### Key Observations
* ThinkPRM consistently outperforms both DiscPRM and LLM-as-a-judge.
* DiscPRM maintains a relatively constant, but lower, F1-score regardless of the number of tokens.
* LLM-as-a-judge shows a slight decrease in performance as the number of tokens increases.
* The performance gains from ThinkPRM appear to saturate after 16K tokens.
### Interpretation
The data suggests that increasing the "thinking" capacity (number of tokens) significantly improves the performance of the ThinkPRM method on the ProcessBench dataset, but the benefits diminish beyond 16K tokens. DiscPRM does not benefit from increased token capacity, indicating it is not leveraging the additional context. LLM-as-a-judge's performance slightly degrades with more tokens, potentially due to increased noise or computational challenges. This implies that ThinkPRM is the most effective method for this task, but there are diminishing returns to increasing the token limit. The flat performance of DiscPRM suggests it may be a simpler or less context-aware approach. The slight decline in LLM-as-a-judge performance is an interesting anomaly that warrants further investigation. The chart highlights the importance of model architecture and context utilization in verification tasks.