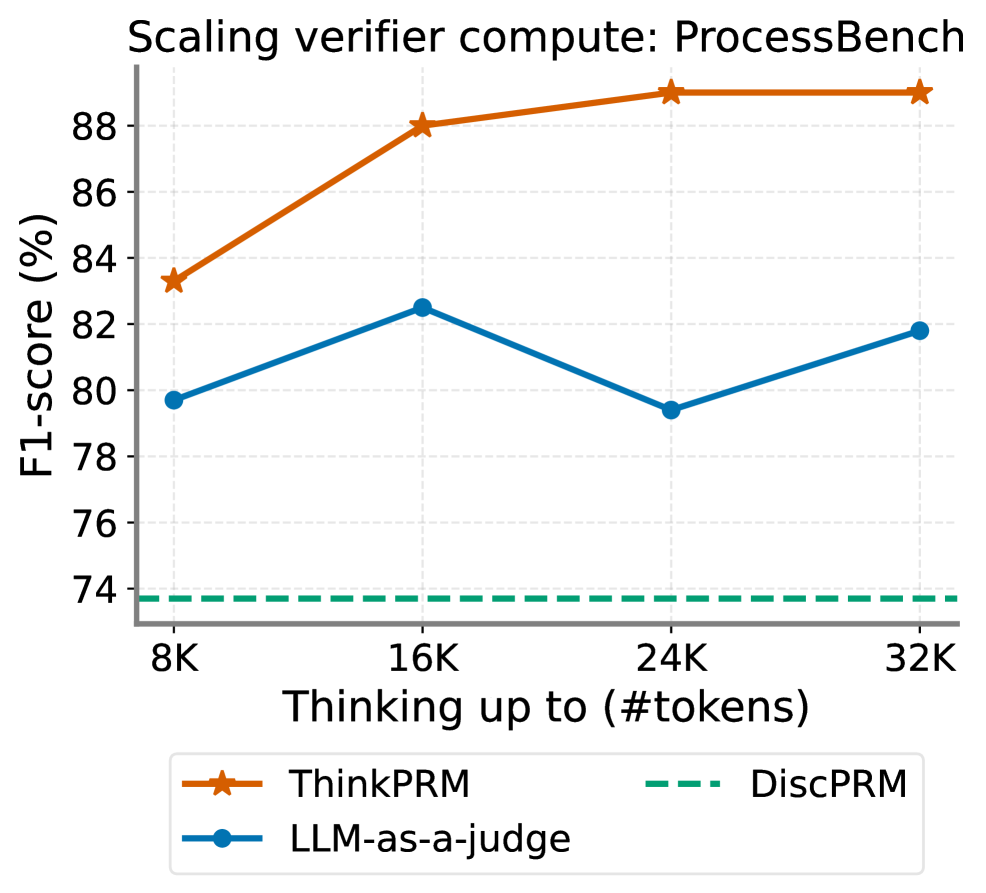
## Line Chart: Scaling verifier compute: ProcessBench
### Overview
The chart compares the performance of three scaling approaches (ThinkPRM, LLM-as-a-judge, DiscPRM) across different token scales (8K to 32K) using F1-score (%) as the metric. The data shows distinct scaling behaviors for each method.
### Components/Axes
- **X-axis**: "Thinking up to (#tokens)" with markers at 8K, 16K, 24K, and 32K
- **Y-axis**: "F1-score (%)" ranging from 74% to 90% in 2% increments
- **Legend**: Located at bottom center, with:
- Orange line with star markers: ThinkPRM
- Blue line with circle markers: LLM-as-a-judge
- Green dashed line: DiscPRM
### Detailed Analysis
1. **ThinkPRM (Orange Line)**:
- 8K tokens: ~83.2% F1-score
- 16K tokens: ~88.1% F1-score
- 24K tokens: ~89.0% F1-score
- 32K tokens: ~89.0% F1-score
- Trend: Steep upward trajectory from 8K to 16K, then plateaus
2. **LLM-as-a-judge (Blue Line)**:
- 8K tokens: ~79.5% F1-score
- 16K tokens: ~82.5% F1-score
- 24K tokens: ~79.0% F1-score
- 32K tokens: ~81.5% F1-score
- Trend: Initial improvement at 16K, followed by decline and partial recovery
3. **DiscPRM (Green Dashed Line)**:
- Constant ~73.5% F1-score across all token scales
- Trend: Flat line with no variation
### Key Observations
- ThinkPRM demonstrates the strongest scaling performance, achieving near-90% F1-score at higher token counts
- LLM-as-a-judge shows inconsistent scaling with a notable performance drop at 24K tokens
- DiscPRM maintains consistently low performance regardless of token scale
- All methods show diminishing returns beyond 16K tokens
### Interpretation
The data suggests that ThinkPRM effectively leverages increased computational resources (token scaling) to improve performance, with significant gains observed between 8K and 16K tokens. The plateau at 24K/32K tokens indicates potential optimization limits. LLM-as-a-judge's performance volatility implies possible instability in scaling strategies, while DiscPRM's flat performance suggests fundamental limitations in its approach. These findings highlight the importance of architectural choices in scaling verifier compute systems, with ThinkPRM emerging as the most effective method for this specific benchmark.