## Scatter Plot: Relation Scores Across NLP Tasks for Language Models
### Overview
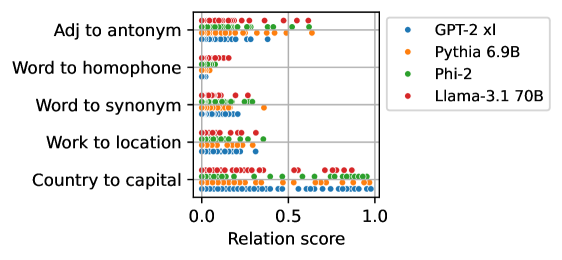
The image is a scatter plot comparing relation scores across five natural language processing (NLP) tasks for four language models: GPT-2 xl, Pythia 6.9B, Phi-2, and Llama-3.1 70B. The x-axis represents relation scores (0.0–1.0), and the y-axis lists NLP tasks. Data points are color-coded by model.
### Components/Axes
- **Y-Axis (Tasks)**:
1. Adj to antonym
2. Word to homophone
3. Word to synonym
4. Work to location
5. Country to capital
- **X-Axis (Relation Score)**:
Scale from 0.0 to 1.0, with no intermediate markers.
- **Legend**:
- Blue: GPT-2 xl
- Orange: Pythia 6.9B
- Green: Phi-2
- Red: Llama-3.1 70B
### Detailed Analysis
1. **Adj to antonym**:
- Llama-3.1 70B (red): ~0.8
- Phi-2 (green): ~0.7
- GPT-2 xl (blue): ~0.6
- Pythia 6.9B (orange): ~0.6
2. **Word to homophone**:
- Llama-3.1 70B (red): ~0.4
- Phi-2 (green): ~0.3
- GPT-2 xl (blue): ~0.2
- Pythia 6.9B (orange): ~0.1
3. **Word to synonym**:
- Llama-3.1 70B (red): ~0.7
- Phi-2 (green): ~0.6
- GPT-2 xl (blue): ~0.5
- Pythia 6.9B (orange): ~0.4
4. **Work to location**:
- Llama-3.1 70B (red): ~0.6
- Phi-2 (green): ~0.5
- GPT-2 xl (blue): ~0.4
- Pythia 6.9B (orange): ~0.3
5. **Country to capital**:
- Llama-3.1 70B (red): ~0.9
- Phi-2 (green): ~0.85
- GPT-2 xl (blue): ~0.8
- Pythia 6.9B (orange): ~0.75
### Key Observations
- **Llama-3.1 70B** consistently achieves the highest scores across all tasks, with the largest margin in "Country to capital" (~0.9).
- **Phi-2** outperforms GPT-2 xl and Pythia 6.9B in most tasks but lags behind Llama-3.1 70B.
- **Pythia 6.9B** has the lowest scores overall, particularly in "Word to homophone" (~0.1).
- **Task difficulty**: "Country to capital" is the easiest (highest scores), while "Word to homophone" is the hardest (lowest scores).
### Interpretation
The data suggests that **Llama-3.1 70B** demonstrates superior relational reasoning capabilities compared to other models, likely due to its larger parameter size (70B vs. 6.9B/2B/1.3B). The performance gap between Llama-3.1 70B and smaller models (Phi-2, GPT-2 xl, Pythia 6.9B) highlights the impact of model scale on NLP task performance.
The clustering of scores in "Country to capital" (~0.75–0.9) indicates this task is relatively straightforward for all models, possibly due to its reliance on factual knowledge rather than nuanced semantic relationships. Conversely, "Word to homophone" (~0.1–0.4) reflects the complexity of homophone detection, which requires deeper contextual understanding.
Phi-2’s mid-tier performance suggests it balances efficiency and capability better than GPT-2 xl or Pythia 6.9B, while Pythia 6.9B’s poor performance may stem from architectural limitations or training data constraints.
This analysis underscores the trade-offs between model size, training data, and task-specific performance in NLP systems.