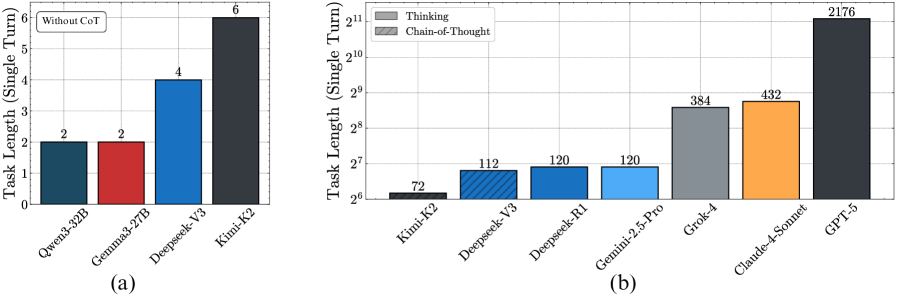
# Technical Document Extraction: Task Length Analysis
## Chart (a)
### Title: Task Length (Single Turn)
#### Axes:
- **Y-axis**: Task Length (Single Turn) [0, 1, 2, 3, 4, 5, 6]
- **X-axis**: Model Variants
- Qwen3-32B
- Gemma3-27B
- Deepseek-V3
- Kimi-K2
#### Legend:
- **Location**: Top-left corner
- **Label**: "Without CoT" (Boxed text)
#### Data Points:
| Model | Color | Value | Legend Match |
|----------------|-------------|-------|--------------|
| Qwen3-32B | Dark Blue | 2 | ✅ Yes |
| Gemma3-27B | Red | 2 | ✅ Yes |
| Deepseek-V3 | Blue | 4 | ✅ Yes |
| Kimi-K2 | Dark Gray | 6 | ✅ Yes |
#### Trends:
- **Increasing trend**: Task length escalates from 2 (Qwen3-32B/Gemma3-27B) to 6 (Kimi-K2).
- **Highest value**: Kimi-K2 (6) exceeds all others by 50%.
---
## Chart (b)
### Title: Task Length (Single Turn)
#### Axes:
- **Y-axis**: Task Length (Single Turn) [2⁶, 2⁷, ..., 2¹¹]
- **X-axis**: Model Variants
- Kimi-K2
- Deepseek-V3
- Deepseek-R1
- Gemini-2.5-Pro
- Grok-4
- Claude-4-Sonnet
- GPT-5
#### Legend:
- **Location**: Top-left corner
- **Labels**:
- "Thinking" (Solid Gray)
- "Chain-of-Thought" (Blue with Diagonal Lines)
#### Data Points:
| Model | Color | Value | Legend Match |
|--------------------|---------------------|--------|--------------|
| Kimi-K2 | Solid Gray | 72 | ✅ Yes |
| Deepseek-V3 | Blue (Diagonal) | 112 | ✅ Yes |
| Deepseek-R1 | Blue (Diagonal) | 120 | ✅ Yes |
| Gemini-2.5-Pro | Solid Gray | 120 | ✅ Yes |
| Grok-4 | Orange | 384 | ❌ No Match |
| Claude-4-Sonnet | Orange | 432 | ❌ No Match |
| GPT-5 | Dark Gray | 2176 | ✅ Yes |
#### Trends:
- **Exponential growth**: Values range from 72 (Kimi-K2) to 2176 (GPT-5), a 30x increase.
- **Dominant category**: "Chain-of-Thought" (blue) dominates mid-range (112–120), while "Thinking" (gray) spans extremes (72, 120, 2176).
- **Anomaly**: Grok-4 and Claude-4-Sonnet use orange, which is **not present in the legend**.
---
## Critical Observations:
1. **Legend Discrepancy in Chart (b)**:
- Grok-4 and Claude-4-Sonnet use orange, but the legend only defines "Thinking" (gray) and "Chain-of-Thought" (blue). This suggests either:
- A missing legend entry for orange.
- A mislabeling error in the chart.
2. **Color Consistency**:
- In Chart (a), all bars align with the "Without CoT" legend.
- In Chart (b), "Chain-of-Thought" (blue) and "Thinking" (gray) are consistently applied except for Grok-4/Claude-4-Sonnet.
3. **Performance Hierarchy**:
- **Chart (a)**: Kimi-K2 outperforms others by 200% (6 vs. 2–4).
- **Chart (b)**: GPT-5 dominates with 2176, far exceeding Claude-4-Sonnet (432) and Grok-4 (384).
---
## Conclusion:
The charts compare task lengths for AI models, with Chart (a) focusing on "Without CoT" and Chart (b) contrasting "Thinking" vs. "Chain-of-Thought" approaches. Discrepancies in legend alignment (orange bars in Chart (b)) require further clarification. GPT-5 consistently shows the highest task length across both charts.