## Bar Charts: LLM Call Distribution for Different Datasets
### Overview
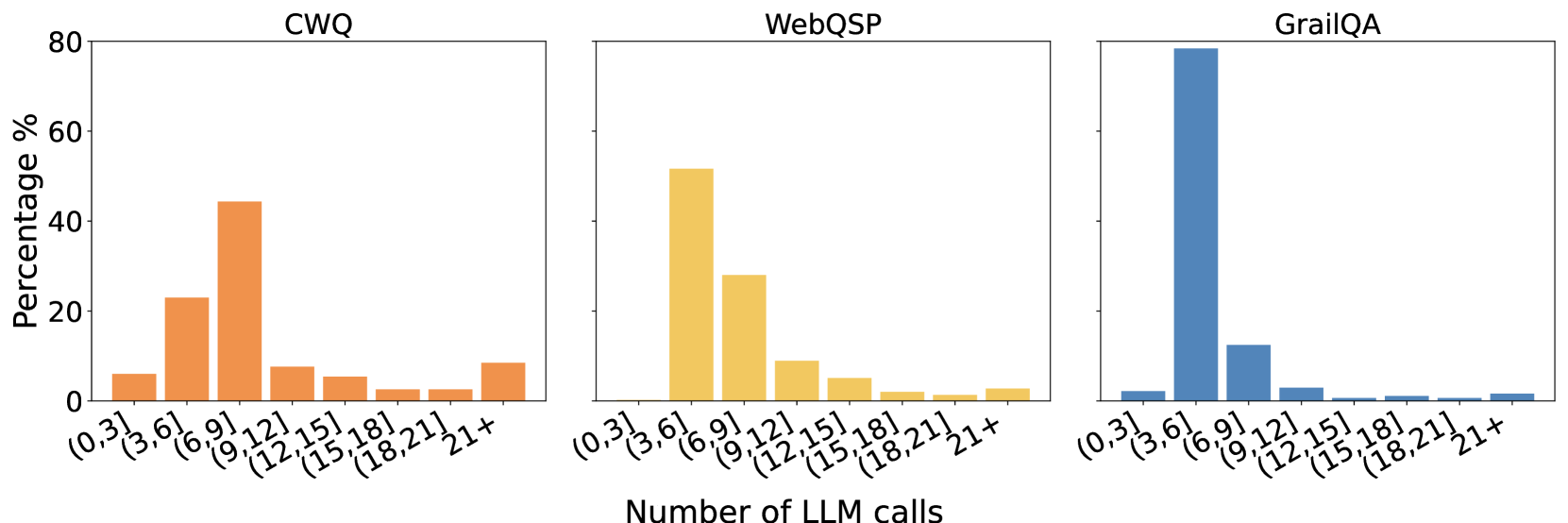
The image presents three bar charts, each displaying the distribution of the number of Large Language Model (LLM) calls for different datasets: CWQ, WebQSP, and GrailQA. The x-axis represents the number of LLM calls, grouped into intervals, and the y-axis represents the percentage of occurrences within each interval.
### Components/Axes
* **Titles (Top of each chart):**
* Left Chart: CWQ
* Middle Chart: WebQSP
* Right Chart: GrailQA
* **X-Axis Label (Shared):** "Number of LLM calls"
* **Y-Axis Label (Shared):** "Percentage %"
* Y-Axis Scale: 0 to 80, with tick marks at 0, 20, 40, 60, and 80.
* **X-Axis Categories (Shared):**
* (0,3]
* (3,6]
* (6,9]
* (9,12]
* (12,15]
* (15,18]
* (18,21]
* 21+
### Detailed Analysis
**1. CWQ (Left Chart):**
* Bar color: Orange
* Trend: The distribution is skewed towards higher numbers of LLM calls.
* (0,3]: ~7%
* (3,6]: ~23%
* (6,9]: ~44%
* (9,12]: ~9%
* (12,15]: ~6%
* (15,18]: ~3%
* (18,21]: ~3%
* 21+: ~9%
**2. WebQSP (Middle Chart):**
* Bar color: Yellow
* Trend: The distribution is skewed towards lower numbers of LLM calls.
* (0,3]: ~52%
* (3,6]: ~28%
* (6,9]: ~10%
* (9,12]: ~6%
* (12,15]: ~2%
* (15,18]: ~1%
* (18,21]: ~1%
* 21+: ~2%
**3. GrailQA (Right Chart):**
* Bar color: Blue
* Trend: The distribution is heavily concentrated in the lowest interval.
* (0,3]: ~78%
* (3,6]: ~13%
* (6,9]: ~4%
* (9,12]: ~2%
* (12,15]: ~1%
* (15,18]: ~0.5%
* (18,21]: ~0.5%
* 21+: ~1%
### Key Observations
* **CWQ:** Has a peak in the (6,9] interval, indicating a higher usage of LLM calls compared to the other datasets.
* **WebQSP:** Shows a significant percentage of occurrences in the (0,3] interval, suggesting that most instances require very few LLM calls.
* **GrailQA:** Is heavily concentrated in the (0,3] interval, indicating that the vast majority of instances require very few LLM calls.
### Interpretation
The charts illustrate the distribution of LLM calls required for different datasets. GrailQA and WebQSP appear to be solvable with fewer LLM calls compared to CWQ. The CWQ dataset has a more even distribution, with a peak in the (6,9] range, suggesting that it requires a more substantial number of LLM calls to resolve. The differences in these distributions likely reflect the complexity and nature of the questions or tasks within each dataset. The concentration of GrailQA in the (0,3] interval suggests that it may consist of simpler queries or tasks that can be resolved with minimal interaction with the LLM.