## Heatmap: Prompt Transferability Matrix
### Overview
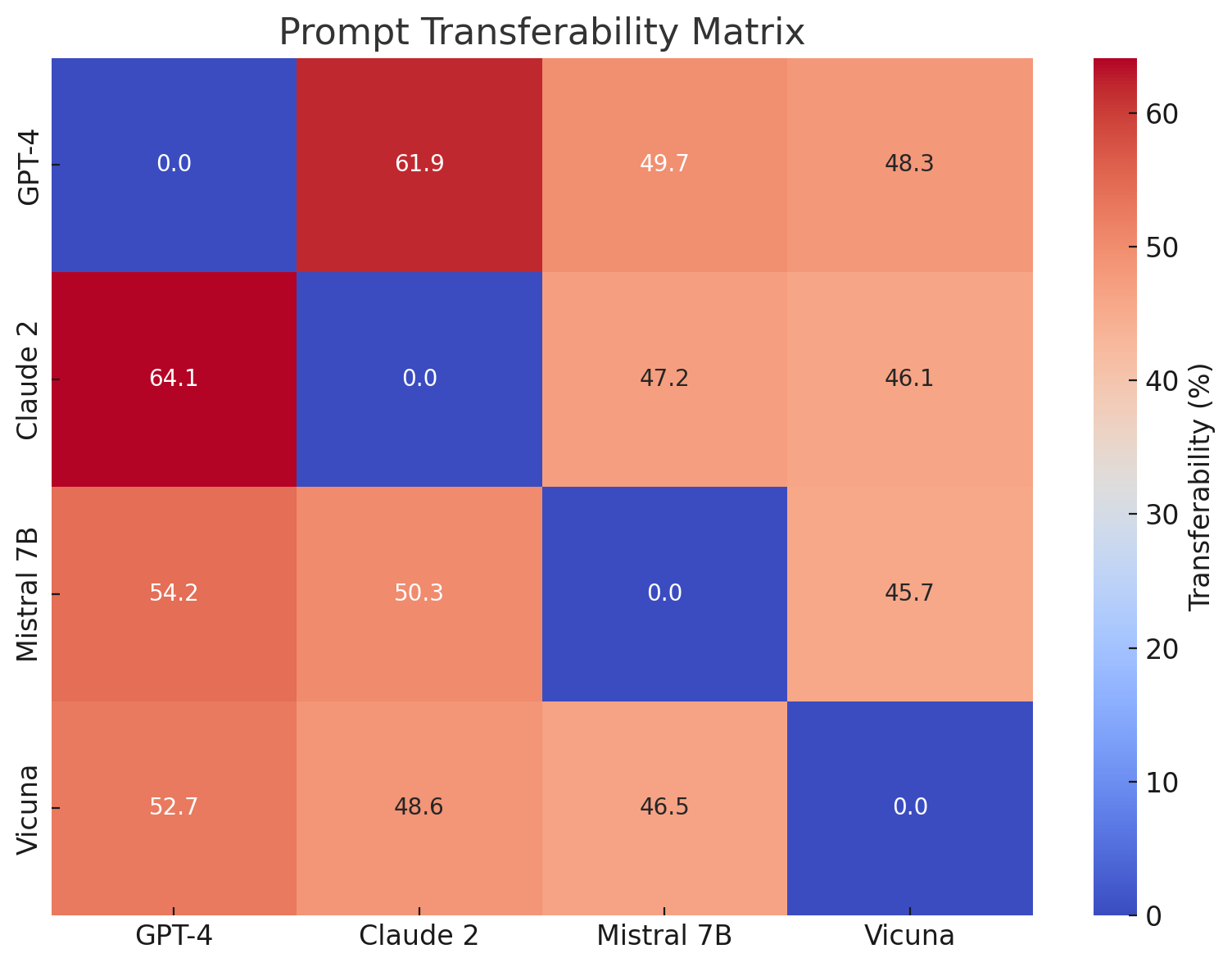
This image presents a heatmap visualizing the prompt transferability between four Large Language Models (LLMs): GPT-4, Claude 2, Mistral 7B, and Vicuna. The color intensity represents the transferability percentage, with darker blues indicating lower transferability and brighter reds indicating higher transferability. The matrix shows the performance of prompts designed for one model when applied to another.
### Components/Axes
* **Title:** "Prompt Transferability Matrix" (centered at the top)
* **X-axis:** LLMs - GPT-4, Claude 2, Mistral 7B, Vicuna (listed horizontally)
* **Y-axis:** LLMs - GPT-4, Claude 2, Mistral 7B, Vicuna (listed vertically)
* **Color Scale/Legend:** Located on the right side of the heatmap, ranging from 0% (dark blue) to 60% (bright red). The scale is labeled "Transferability (%)".
* **Cells:** Each cell represents the transferability percentage between the corresponding LLM on the X and Y axes.
### Detailed Analysis
The heatmap is a 4x4 matrix. The values within each cell are as follows:
* **GPT-4:**
* GPT-4 to GPT-4: 0.0% (dark blue)
* GPT-4 to Claude 2: 61.9% (bright red)
* GPT-4 to Mistral 7B: 49.7% (orange-red)
* GPT-4 to Vicuna: 48.3% (orange-red)
* **Claude 2:**
* Claude 2 to GPT-4: 64.1% (bright red)
* Claude 2 to Claude 2: 0.0% (dark blue)
* Claude 2 to Mistral 7B: 47.2% (orange-red)
* Claude 2 to Vicuna: 46.1% (orange-red)
* **Mistral 7B:**
* Mistral 7B to GPT-4: 54.2% (orange-red)
* Mistral 7B to Claude 2: 50.3% (orange-red)
* Mistral 7B to Mistral 7B: 0.0% (dark blue)
* Mistral 7B to Vicuna: 45.7% (orange-red)
* **Vicuna:**
* Vicuna to GPT-4: 52.7% (orange-red)
* Vicuna to Claude 2: 48.6% (orange-red)
* Vicuna to Mistral 7B: 46.5% (orange-red)
* Vicuna to Vicuna: 0.0% (dark blue)
The diagonal cells (GPT-4 to GPT-4, Claude 2 to Claude 2, etc.) all have a transferability of 0.0%. This indicates that prompts optimized for a specific model perform poorly when used with the same model, which is counterintuitive.
### Key Observations
* **Highest Transferability:** The highest transferability scores are between GPT-4 and Claude 2 (61.9% and 64.1%), and between Claude 2 and GPT-4.
* **Lowest Transferability:** The lowest transferability scores are along the diagonal, indicating poor self-transferability.
* **Symmetry:** The matrix is approximately symmetric, meaning the transferability from Model A to Model B is roughly the same as from Model B to Model A.
* **Mistral 7B and Vicuna:** These models show relatively consistent transferability scores to other models, generally in the 45-55% range.
### Interpretation
The data suggests that prompts designed for one LLM do not necessarily translate well to other LLMs, even those with similar architectures. The 0% self-transferability is a particularly striking finding, implying that prompts highly tuned for a specific model may actually *degrade* performance when re-applied to the same model. This could be due to subtle differences in the models' internal representations or training data.
The high transferability between GPT-4 and Claude 2 suggests these models share some common underlying capabilities or prompt understanding mechanisms. The lower transferability scores for Mistral 7B and Vicuna may indicate that these models have more distinct prompt sensitivities or require different prompting strategies.
The approximate symmetry of the matrix suggests a degree of reciprocity in prompt transferability. If a prompt works well when transferred from Model A to Model B, it's likely to work reasonably well in the reverse direction.
This data is valuable for understanding the limitations of prompt engineering and the importance of tailoring prompts to specific LLMs. It also highlights the need for research into more robust and transferable prompting techniques.