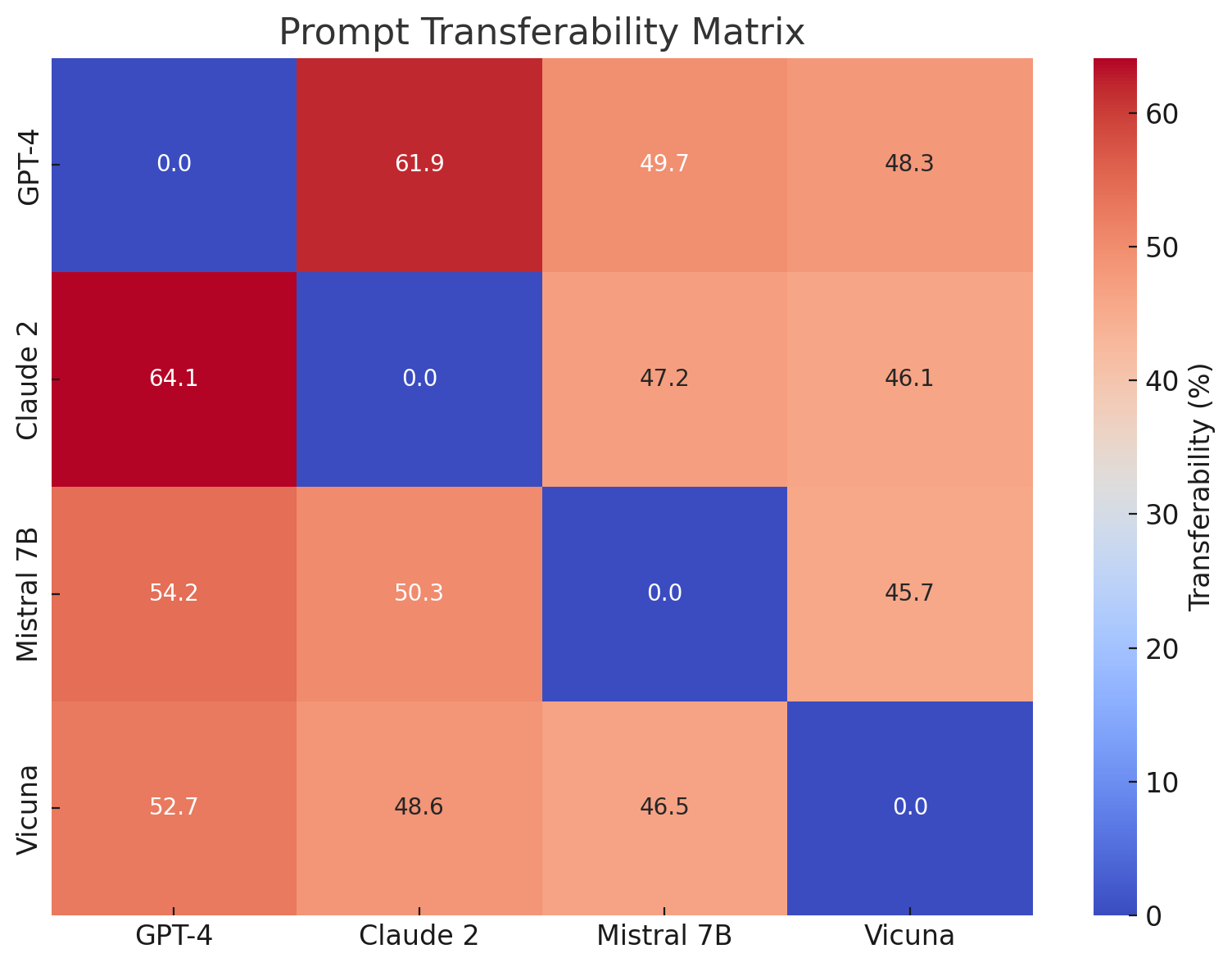
## Heatmap: Prompt Transferability Matrix
### Overview
The image is a heatmap titled "Prompt Transferability Matrix." It visualizes the percentage of transferability of prompts between four different large language models (LLMs). The matrix is a 4x4 grid where each cell represents the transferability score from a source model (rows) to a target model (columns). The diagonal cells, representing transfer to the same model, are all 0.0%.
### Components/Axes
* **Title:** "Prompt Transferability Matrix" (centered at the top).
* **Y-Axis (Rows - Source Models):** Labeled on the left side. From top to bottom: "GPT-4", "Claude 2", "Mistral 7B", "Vicuna".
* **X-Axis (Columns - Target Models):** Labeled at the bottom. From left to right: "GPT-4", "Claude 2", "Mistral 7B", "Vicuna".
* **Color Bar/Legend:** Positioned on the right side of the heatmap. It is a vertical gradient bar labeled "Transferability (%)". The scale runs from 0 (dark blue) at the bottom to approximately 65 (dark red) at the top, with numerical ticks at 0, 10, 20, 30, 40, 50, and 60.
* **Data Cells:** Each cell in the 4x4 grid contains a numerical value representing the transferability percentage and is colored according to the legend.
### Detailed Analysis
The matrix contains the following exact numerical values, read row by row (source model) and column by column (target model):
**Row 1: Source = GPT-4**
* To GPT-4: **0.0** (Dark Blue)
* To Claude 2: **61.9** (Dark Red)
* To Mistral 7B: **49.7** (Light Orange)
* To Vicuna: **48.3** (Light Orange)
**Row 2: Source = Claude 2**
* To GPT-4: **64.1** (Dark Red - Highest value in the matrix)
* To Claude 2: **0.0** (Dark Blue)
* To Mistral 7B: **47.2** (Light Orange)
* To Vicuna: **46.1** (Light Orange)
**Row 3: Source = Mistral 7B**
* To GPT-4: **54.2** (Orange)
* To Claude 2: **50.3** (Orange)
* To Mistral 7B: **0.0** (Dark Blue)
* To Vicuna: **45.7** (Light Orange)
**Row 4: Source = Vicuna**
* To GPT-4: **52.7** (Orange)
* To Claude 2: **48.6** (Light Orange)
* To Mistral 7B: **46.5** (Light Orange)
* To Vicuna: **0.0** (Dark Blue)
### Key Observations
1. **Diagonal Zeroes:** All cells where the source and target model are the same (GPT-4→GPT-4, etc.) have a value of 0.0, indicated by dark blue. This is a baseline, as a prompt does not need to "transfer" to itself.
2. **Highest Transferability:** The highest recorded transferability is **64.1%** from **Claude 2 (source) to GPT-4 (target)**. The second highest is **61.9%** from **GPT-4 (source) to Claude 2 (target)**. This indicates a strong, bidirectional relationship between these two models.
3. **Moderate Transferability:** All other off-diagonal values fall within a relatively narrow range, approximately between **45.7% and 54.2%**. This suggests a consistent, moderate level of prompt transferability among the other model pairs (involving Mistral 7B and Vicuna).
4. **Color Pattern:** The heatmap shows a clear pattern where the cells for GPT-4↔Claude 2 are the most intensely red (highest values). The cells involving Mistral 7B and Vicuna as either source or target are predominantly orange/light orange, indicating mid-range values. The diagonal is uniformly blue.
### Interpretation
This heatmap provides a quantitative measure of how effectively prompts designed for one LLM can be used with another. The data suggests the following:
* **Strong Model Affinity:** GPT-4 and Claude 2 exhibit a particularly high degree of mutual prompt transferability (both >60%). This could imply similarities in their underlying architecture, training data, or instruction-following fine-tuning, making prompts crafted for one largely effective on the other.
* **General Cross-Model Utility:** The fact that all non-zero values are above 45% indicates that prompts have significant, though not perfect, cross-model utility. A prompt engineered for one model has a reasonable chance of working on another, which is valuable for developers and researchers working across multiple platforms.
* **Asymmetry:** While generally high, transferability is not perfectly symmetric. For example, prompts from Claude 2 transfer slightly better to GPT-4 (64.1%) than vice-versa (61.9%). Similarly, prompts from Mistral 7B transfer better to GPT-4 (54.2%) than to Vicuna (45.7%). These asymmetries may reflect differences in model capability or the specificity of the prompts tested.
* **Practical Implication:** The matrix is a tool for understanding model interoperability. High transferability scores suggest that prompt optimization efforts for one model may yield benefits on another, potentially reducing redundant work. The lower scores (though still >45%) for pairs involving Mistral 7B and Vicuna indicate that more model-specific prompt tuning might be required for optimal performance when switching between these and the other models.