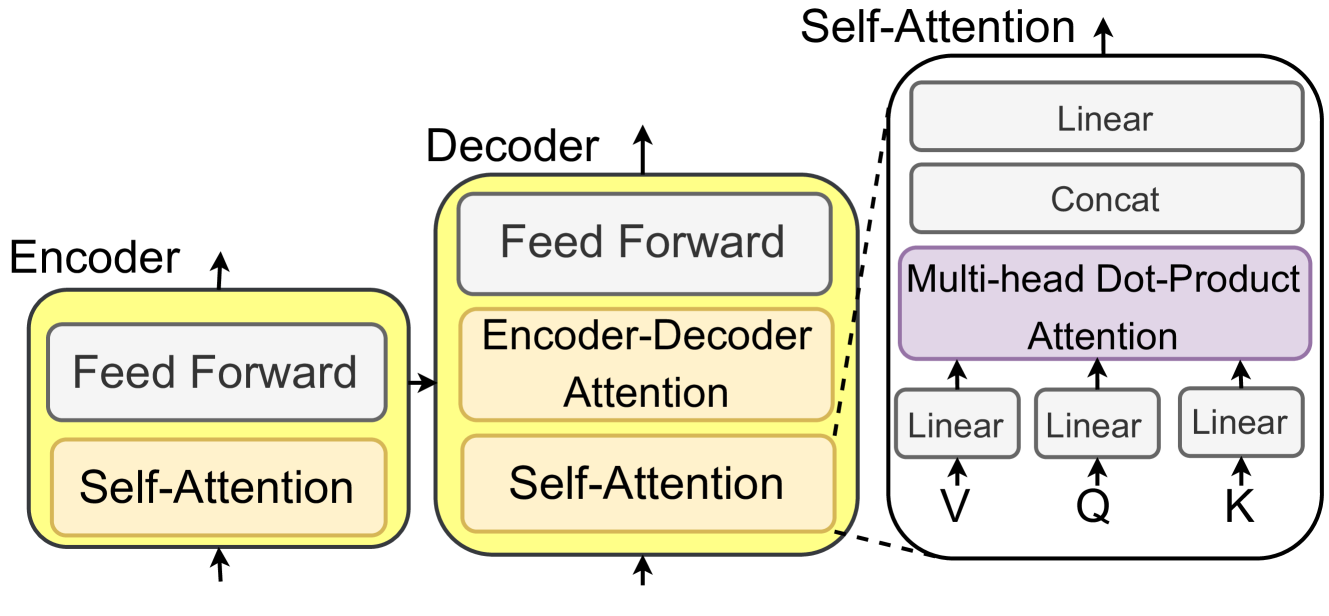
## Diagram: Encoder-Decoder Architecture with Attention
### Overview
The image depicts a high-level block diagram of an encoder-decoder architecture, likely used in sequence-to-sequence models, with a focus on attention mechanisms. The diagram shows the flow of information through the encoder and decoder, highlighting the self-attention and feed-forward layers within each. A detailed view of the self-attention mechanism is also provided.
### Components/Axes
* **Encoder:** Labeled on the left, with an upward arrow indicating the direction of information flow.
* Contains two blocks: "Feed Forward" (top) and "Self-Attention" (bottom). Both blocks are contained within a larger rounded rectangle with a yellow outline.
* **Decoder:** Labeled in the center, with an upward arrow indicating the direction of information flow.
* Contains three blocks: "Feed Forward" (top), "Encoder-Decoder Attention" (middle), and "Self-Attention" (bottom). All blocks are contained within a larger rounded rectangle with a yellow outline.
* **Self-Attention (Detailed View):** Located on the right, enclosed in a rounded rectangle with a dashed line. An upward arrow indicates the direction of information flow.
* Contains four blocks: "Linear" (top), "Concat" (second from top), "Multi-head Dot-Product Attention" (third from top, colored purple), and three "Linear" blocks at the bottom.
* The three "Linear" blocks at the bottom have arrows pointing upwards from "V", "Q", and "K" respectively.
### Detailed Analysis
* **Encoder:**
* Input flows into the "Self-Attention" block.
* Output from "Self-Attention" flows into the "Feed Forward" block.
* Output from "Feed Forward" is the encoder's output.
* **Decoder:**
* Input flows into the "Self-Attention" block.
* Output from "Self-Attention" flows into the "Encoder-Decoder Attention" block.
* Output from "Encoder-Decoder Attention" flows into the "Feed Forward" block.
* Output from "Feed Forward" is the decoder's output.
* **Self-Attention (Detailed View):**
* Inputs "V", "Q", and "K" each pass through a "Linear" transformation.
* The outputs of the "Linear" transformations feed into the "Multi-head Dot-Product Attention" block.
* The output of the "Multi-head Dot-Product Attention" block feeds into the "Concat" block.
* The output of the "Concat" block feeds into the "Linear" block.
* The output of the "Linear" block is the output of the self-attention mechanism.
### Key Observations
* The diagram highlights the key components of an encoder-decoder architecture, including the feed-forward and attention mechanisms.
* The detailed view of the self-attention mechanism shows the flow of information through the linear transformations, dot-product attention, and concatenation layers.
* The use of "Self-Attention" in both the encoder and decoder suggests that the model is using self-attention to capture relationships within the input and output sequences.
* The "Encoder-Decoder Attention" block in the decoder suggests that the model is using attention to align the input and output sequences.
### Interpretation
The diagram illustrates a common architecture used in sequence-to-sequence tasks, such as machine translation or text summarization. The encoder processes the input sequence, and the decoder generates the output sequence. The attention mechanisms allow the model to focus on the most relevant parts of the input sequence when generating the output sequence. The self-attention mechanism allows the model to capture relationships within the input and output sequences, while the encoder-decoder attention mechanism allows the model to align the input and output sequences. The multi-head dot-product attention is a specific type of attention mechanism that allows the model to attend to different parts of the input sequence in parallel. The linear and concat layers are used to transform and combine the outputs of the attention mechanism.