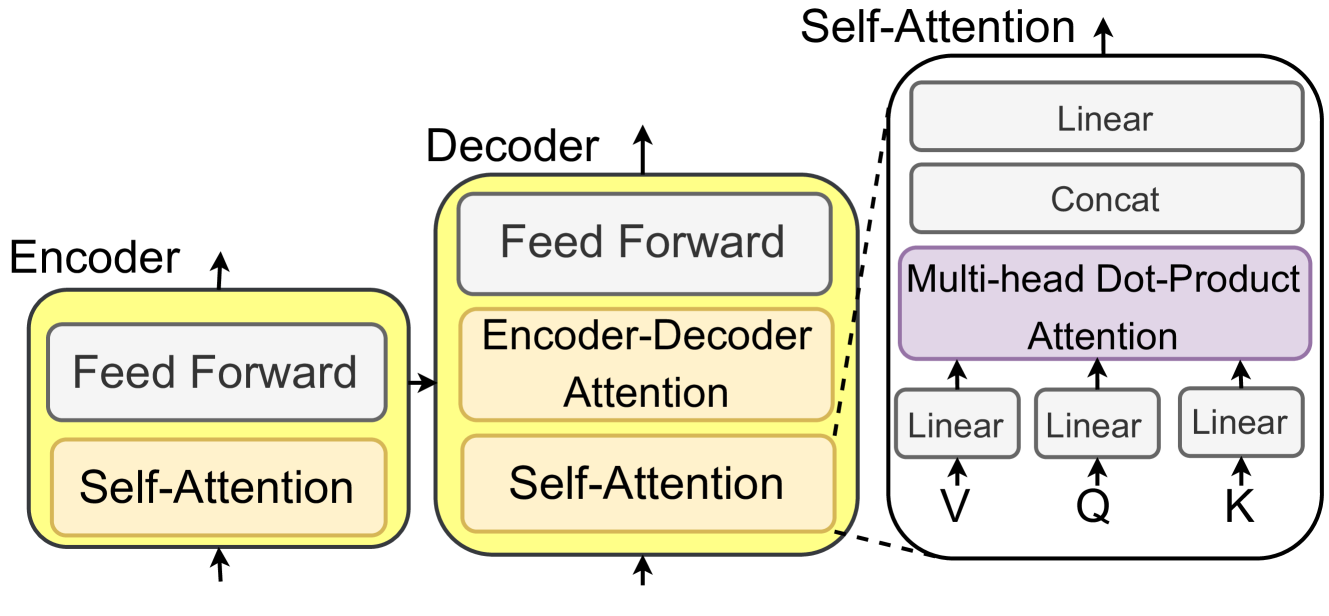
## Diagram: Transformer Architecture (Encoder-Decoder with Multi-Head Attention)
### Overview
This image is a technical diagram illustrating the high-level architecture of a Transformer model, a foundational neural network architecture for sequence-to-sequence tasks like machine translation. It visually decomposes the model into its primary Encoder and Decoder blocks and provides an expanded view of the internal Self-Attention mechanism.
### Components/Axes
The diagram is organized into three main visual regions from left to right:
1. **Encoder Block (Left):**
* A yellow rounded rectangle labeled **"Encoder"** at the top.
* Contains two internal sub-layer boxes:
* A white box labeled **"Feed Forward"**.
* A light orange box labeled **"Self-Attention"**.
* An upward-pointing arrow emerges from the top of the Encoder block.
* An upward-pointing arrow enters the bottom of the Encoder block.
* A rightward-pointing arrow connects the Encoder block to the Decoder block.
2. **Decoder Block (Center):**
* A yellow rounded rectangle labeled **"Decoder"** at the top.
* Contains three internal sub-layer boxes:
* A white box labeled **"Feed Forward"**.
* A light orange box labeled **"Encoder-Decoder Attention"**.
* A light orange box labeled **"Self-Attention"**.
* An upward-pointing arrow emerges from the top of the Decoder block.
* An upward-pointing arrow enters the bottom of the Decoder block.
* A dashed line connects the Decoder's "Self-Attention" box to the expanded view on the right.
3. **Expanded Self-Attention Mechanism (Right):**
* A large, light-gray rounded rectangle labeled **"Self-Attention"** at the top.
* This block details the components of the Multi-Head Attention sub-layer.
* **Internal Components (from bottom to top):**
* Three small white boxes at the bottom, each labeled **"Linear"**.
* Below these boxes are the input labels: **"V"**, **"Q"**, and **"K"** (from left to right), with upward arrows pointing to their respective Linear boxes.
* Upward arrows from the three Linear boxes point to a large purple box labeled **"Multi-head Dot-Product Attention"**.
* An upward arrow from the purple box points to a white box labeled **"Concat"**.
* An upward arrow from the "Concat" box points to a final white box labeled **"Linear"**.
* An upward arrow emerges from the top of the entire "Self-Attention" block.
### Detailed Analysis
* **Data Flow:** The diagram depicts a clear sequential and hierarchical flow.
1. Input enters the **Encoder** from the bottom, passes through its Self-Attention and Feed Forward layers, and exits from the top.
2. The Encoder's output is fed sideways into the **Decoder**.
3. The Decoder processes its own input (from below) and the Encoder's output through three layers: its own Self-Attention, the Encoder-Decoder Attention (which uses the Encoder's output), and a Feed Forward network.
4. The final output exits the Decoder from the top.
* **Component Relationships:** The dashed line explicitly links the abstract "Self-Attention" box within the Decoder to its detailed implementation on the right, showing that the right-hand block is a "zoom-in" of that component.
* **Attention Mechanism Details:** The expanded view shows that the Multi-Head Attention mechanism consists of:
* Three separate linear projections for the Value (**V**), Query (**Q**), and Key (**K**) vectors.
* The core **Multi-head Dot-Product Attention** operation.
* A **Concat** (concatenation) operation to combine the outputs from multiple attention heads.
* A final **Linear** projection layer.
### Key Observations
* **Structural Symmetry:** The Encoder and Decoder share a similar internal structure with "Self-Attention" and "Feed Forward" layers, highlighting the modular design.
* **Critical Distinction:** The Decoder contains an additional, unique layer: **"Encoder-Decoder Attention"**. This is the component that allows the Decoder to focus on relevant parts of the input sequence (from the Encoder) while generating the output sequence.
* **Visual Coding:** Color is used functionally:
* Yellow: Main architectural blocks (Encoder, Decoder).
* Light Orange: Attention-based sub-layers.
* Purple: The core multi-head attention operation.
* White: Feed-forward and linear transformation layers.
* **Spatial Grounding:** The legend/labels are integrated directly into the components they describe. The expanded Self-Attention view is positioned to the right of the Decoder, connected by a dashed line originating from the corresponding sub-layer.
### Interpretation
This diagram is a canonical representation of the Transformer architecture introduced in the paper "Attention Is All You Need." It demonstrates the model's core innovation: replacing recurrent layers entirely with attention mechanisms.
* **What it demonstrates:** The architecture enables parallel processing of sequences (unlike RNNs) and captures long-range dependencies effectively through self-attention. The Encoder creates a contextual representation of the input, while the Decoder generates the output one element at a time, using both its own previous outputs (via self-attention) and the Encoder's representation (via encoder-decoder attention).
* **Relationships:** The flow shows a clear separation of concerns. The Encoder is responsible for understanding the input. The Decoder is responsible for generating the output, guided by the Encoder's understanding. The Multi-Head Attention is the fundamental computational engine within both, allowing the model to jointly attend to information from different representation subspaces at different positions.
* **Significance:** This specific diagram is foundational for understanding modern large language models (LLMs). It visually explains how the model processes information in parallel and how the decoder "attends to" the encoder's output, which is the basis for tasks like translation, summarization, and text generation. The expanded view of Multi-Head Attention is crucial for understanding the model's ability to capture complex relationships within the data.