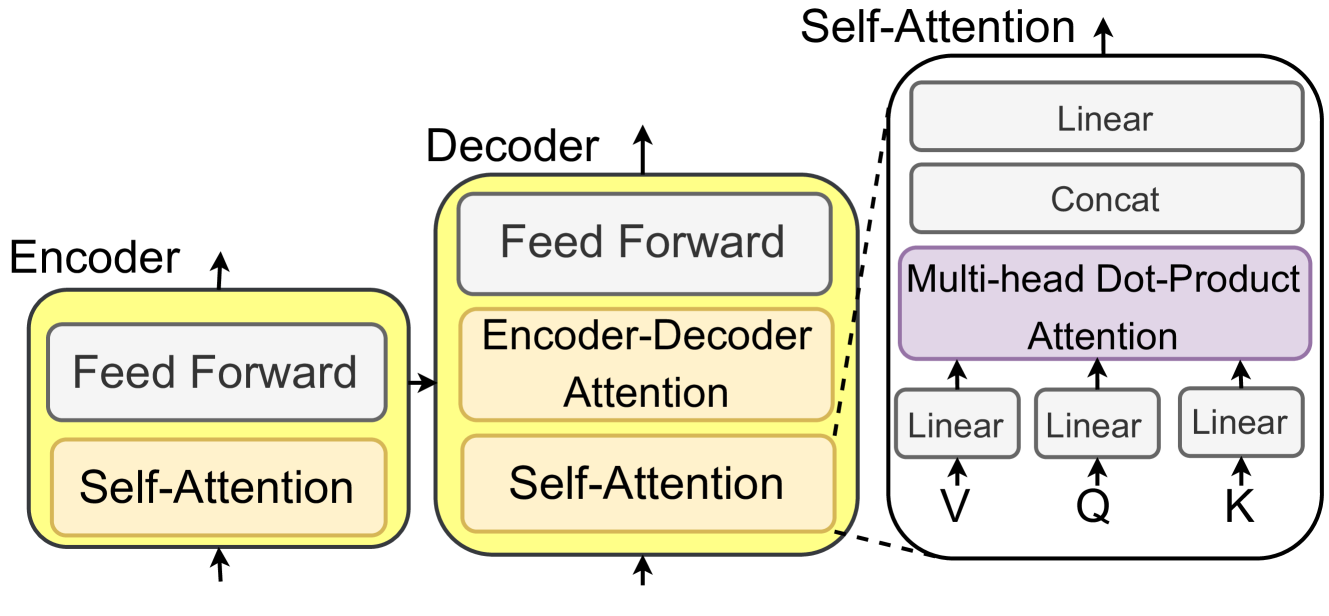
## Diagram: Transformer Architecture Overview
### Overview
The diagram illustrates the core components of a transformer model, focusing on the encoder-decoder structure with attention mechanisms. It highlights self-attention, encoder-decoder attention, and feed-forward layers, with a detailed breakdown of multi-head dot-product attention.
### Components/Axes
- **Encoder**:
- Contains two sub-components:
1. **Self-Attention** (orange block)
2. **Feed Forward** (gray block)
- Arrows indicate sequential processing from bottom to top.
- **Decoder**:
- Contains three sub-components:
1. **Self-Attention** (orange block)
2. **Encoder-Decoder Attention** (orange block)
3. **Feed Forward** (gray block)
- Arrows show vertical flow within the decoder.
- **Multi-Head Dot-Product Attention**:
- Detailed in a separate block (purple) with:
- **Linear** layers for V, Q, K (three separate linear transformations).
- **Concat** step to combine outputs.
- Final **Linear** layer for output.
### Detailed Analysis
- **Encoder**:
- Self-Attention processes input sequences to capture contextual relationships.
- Feed Forward applies non-linear transformations to the attended outputs.
- **Decoder**:
- **Self-Attention**: Ensures autoregressive generation by masking future tokens.
- **Encoder-Decoder Attention**: Allows the decoder to focus on relevant parts of the encoder’s output.
- **Feed Forward**: Final non-linear processing before output generation.
- **Multi-Head Attention**:
- **Q, K, V**: Linear projections of input queries, keys, and values.
- **Dot-Product**: Computes attention scores between queries and keys.
- **Multi-Head**: Parallel attention computations across multiple heads for diverse context capture.
### Key Observations
1. **Color Coding**:
- Encoder/Decoder blocks: Yellow.
- Attention mechanisms: Purple.
- Linear/Concat layers: Gray.
2. **Flow Direction**:
- Encoder processes input first, then decoder generates output using encoder outputs and its own self-attention.
3. **Attention Complexity**:
- Multi-head attention introduces parallelism via multiple linear transformations (Q, K, V).
### Interpretation
This diagram represents the foundational architecture of transformers, emphasizing attention mechanisms for sequence modeling. The encoder-decoder structure enables tasks like translation by aligning input and output sequences. The multi-head attention allows the model to jointly attend to information from different representation subspaces, improving performance on tasks requiring long-range dependencies. The separation of self-attention (context within a sequence) and encoder-decoder attention (cross-sequence context) highlights the model’s ability to handle both local and global dependencies.