\n
## Venn Diagram: Overlap of Token Sets
### Overview
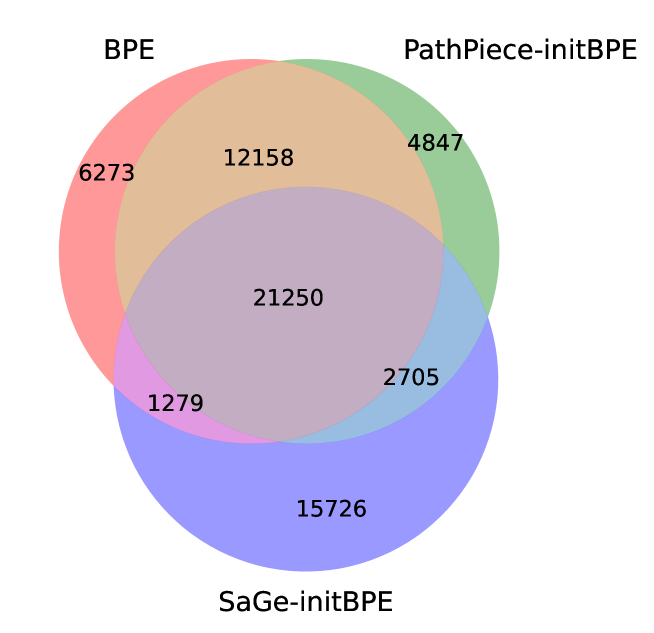
This image is a Venn diagram illustrating the overlap between three sets of tokens: BPE, PathPiece-initBPE, and SaGe-initBPE. The diagram uses overlapping circles to represent the sets, with numbers indicating the number of tokens in each section.
### Components/Axes
The diagram consists of three overlapping circles labeled as follows:
* **BPE** (represented by a red circle, positioned at the top-left)
* **PathPiece-initBPE** (represented by a green circle, positioned at the top-right)
* **SaGe-initBPE** (represented by a blue/purple circle, positioned at the bottom)
The areas of overlap between the circles are labeled with numerical values representing the number of tokens present in those intersections.
### Detailed Analysis
Here's a breakdown of the token counts in each region of the Venn diagram:
* **BPE only:** 6273 tokens
* **PathPiece-initBPE only:** 4847 tokens
* **SaGe-initBPE only:** 15726 tokens
* **BPE and PathPiece-initBPE overlap:** 12158 tokens
* **BPE and SaGe-initBPE overlap:** 1279 tokens
* **PathPiece-initBPE and SaGe-initBPE overlap:** 2705 tokens
* **BPE, PathPiece-initBPE, and SaGe-initBPE overlap:** 21250 tokens
### Key Observations
* SaGe-initBPE has the largest number of unique tokens (15726) compared to the other two sets.
* The intersection of all three sets (BPE, PathPiece-initBPE, and SaGe-initBPE) contains the largest number of tokens (21250), indicating a substantial common vocabulary.
* The overlap between BPE and PathPiece-initBPE (12158) is significantly larger than the overlap between BPE and SaGe-initBPE (1279) or PathPiece-initBPE and SaGe-initBPE (2705).
### Interpretation
The Venn diagram demonstrates the relationships between the token sets used by different Byte Pair Encoding (BPE) variants. The large overlap between all three sets suggests that these methods share a significant portion of their vocabulary. The substantial overlap between BPE and PathPiece-initBPE indicates that PathPiece-initBPE builds upon a similar base vocabulary as standard BPE. The relatively smaller overlaps involving SaGe-initBPE might suggest that it employs a more distinct vocabulary or a different tokenization strategy, despite sharing some common tokens with the other methods. The high number of tokens unique to SaGe-initBPE suggests it may be capturing linguistic features not adequately represented by the other two methods. This information is valuable for understanding the trade-offs between different tokenization approaches in natural language processing tasks.