## Diagram: Latent Token Generation Methods
### Overview
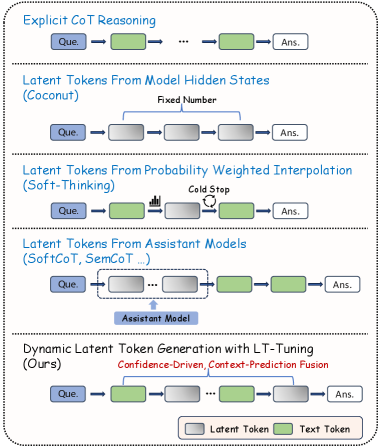
The image presents a comparison of different methods for latent token generation in language models. It illustrates five approaches: Explicit CoT Reasoning, Latent Tokens from Model Hidden States (Coconut), Latent Tokens from Probability Weighted Interpolation (Soft-Thinking), Latent Tokens from Assistant Models (SoftCoT, SemCoT...), and Dynamic Latent Token Generation with LT-Tuning (Ours). The diagram uses a consistent visual language to represent each method, highlighting the flow of information and the role of latent tokens.
### Components/Axes
* **Nodes:** Rectangular boxes labeled "Que." (Question) and "Ans." (Answer) represent the input and output, respectively. Other rectangular boxes, colored either gray or green, represent latent tokens or text tokens.
* **Arrows:** Arrows indicate the flow of information between nodes.
* **Text Labels:** Descriptive text provides the name of each method and additional details about its operation.
* **Legend:** Located at the bottom-right, the legend defines the color scheme: Gray boxes represent "Latent Token," and green boxes represent "Text Token."
### Detailed Analysis
**1. Explicit CoT Reasoning:**
* Starts with a "Que." (Question) node.
* Flows through a green "Text Token" node.
* Continues through a series of gray "Latent Token" nodes, indicated by "...".
* Ends with an "Ans." (Answer) node.
* Trend: Question -> Text Token -> Latent Tokens -> Answer
**2. Latent Tokens From Model Hidden States (Coconut):**
* Starts with a "Que." (Question) node.
* Flows through a gray "Latent Token" node.
* Continues through a fixed number of gray "Latent Token" nodes.
* Ends with an "Ans." (Answer) node.
* Label: "Fixed Number" above the latent tokens.
* Trend: Question -> Latent Tokens (Fixed Number) -> Answer
**3. Latent Tokens From Probability Weighted Interpolation (Soft-Thinking):**
* Starts with a "Que." (Question) node.
* Flows through a green "Text Token" node.
* Flows through a gray "Latent Token" node.
* A "Cold Stop" label is associated with a circular arrow pointing back to the previous latent token.
* Ends with an "Ans." (Answer) node.
* Trend: Question -> Text Token -> Latent Token (with Cold Stop) -> Answer
**4. Latent Tokens From Assistant Models (SoftCoT, SemCoT...):**
* Starts with a "Que." (Question) node.
* Flows through a series of gray "Latent Token" nodes, indicated by "...". These latent tokens are enclosed in a dashed rectangle labeled "Assistant Model".
* Flows through a green "Text Token" node.
* Ends with an "Ans." (Answer) node.
* Trend: Question -> Latent Tokens (Assistant Model) -> Text Token -> Answer
**5. Dynamic Latent Token Generation with LT-Tuning (Ours):**
* Starts with a "Que." (Question) node.
* Flows through a green "Text Token" node.
* Flows through a series of gray "Latent Token" nodes, indicated by "...".
* Ends with an "Ans." (Answer) node.
* Label: "Confidence-Driven, Context-Prediction Fusion" above the latent tokens.
* Trend: Question -> Text Token -> Latent Tokens -> Answer
### Key Observations
* All methods start with a "Que." node and end with an "Ans." node.
* The primary difference between the methods lies in how the latent tokens are generated and integrated into the process.
* Some methods use a fixed number of latent tokens, while others use a dynamic or context-dependent approach.
* The "Soft-Thinking" method introduces a "Cold Stop" mechanism.
* The "Assistant Models" method uses an external model to generate latent tokens.
* The "Ours" method uses "Confidence-Driven, Context-Prediction Fusion" for latent token generation.
### Interpretation
The diagram illustrates the evolution of latent token generation techniques in language models. It highlights the shift from explicit reasoning chains to more sophisticated methods that leverage model hidden states, probability-weighted interpolation, assistant models, and dynamic tuning. The "Ours" method, which uses confidence-driven and context-prediction fusion, represents a more advanced approach to latent token generation. The diagram suggests that the field is moving towards more flexible and adaptive methods for incorporating latent information into language models.