\n
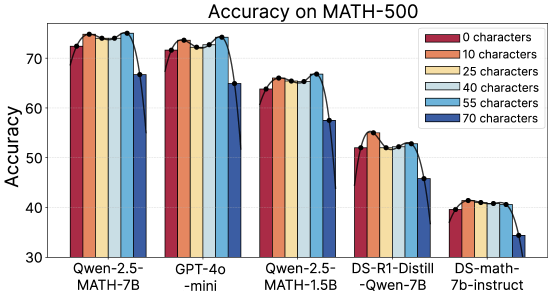
## Bar Chart: Accuracy on MATH-500
### Overview
This bar chart displays the accuracy of several language models on the MATH-500 dataset, broken down by the number of characters in the input. The x-axis represents the different models, and the y-axis represents the accuracy percentage. Each model has a set of bars, one for each character length.
### Components/Axes
* **Title:** Accuracy on MATH-500 (positioned at the top-center)
* **X-axis Label:** Model Name (bottom-center)
* Models: Qwen-2.5-MATH-7B, GPT-4o-mini, Qwen-2.5-MATH-1.5B, DS-R1-Distill-Qwen-7B, DS-math-7b-instruct
* **Y-axis Label:** Accuracy (left-center)
* Scale: 30 to 75, with increments of 10.
* **Legend:** (top-right)
* 0 characters (Red)
* 10 characters (Brown)
* 25 characters (Yellow)
* 40 characters (Light Blue)
* 55 characters (Blue)
* 70 characters (Dark Blue)
### Detailed Analysis
The chart consists of five groups of bars, one for each model. Within each group, there are six bars representing the accuracy for different character lengths.
**Qwen-2.5-MATH-7B:**
* 0 characters: Approximately 73% accuracy.
* 10 characters: Approximately 74% accuracy.
* 25 characters: Approximately 74.5% accuracy.
* 40 characters: Approximately 74% accuracy.
* 55 characters: Approximately 73% accuracy.
* 70 characters: Approximately 72% accuracy.
*Trend: Relatively stable accuracy across character lengths, with a slight peak at 25 characters.*
**GPT-4o-mini:**
* 0 characters: Approximately 72% accuracy.
* 10 characters: Approximately 73% accuracy.
* 25 characters: Approximately 73.5% accuracy.
* 40 characters: Approximately 73% accuracy.
* 55 characters: Approximately 71% accuracy.
* 70 characters: Approximately 68% accuracy.
*Trend: Accuracy generally decreases with increasing character length.*
**Qwen-2.5-MATH-1.5B:**
* 0 characters: Approximately 65% accuracy.
* 10 characters: Approximately 66% accuracy.
* 25 characters: Approximately 67% accuracy.
* 40 characters: Approximately 67% accuracy.
* 55 characters: Approximately 65% accuracy.
* 70 characters: Approximately 64% accuracy.
*Trend: Relatively stable accuracy across character lengths.*
**DS-R1-Distill-Qwen-7B:**
* 0 characters: Approximately 55% accuracy.
* 10 characters: Approximately 56% accuracy.
* 25 characters: Approximately 56% accuracy.
* 40 characters: Approximately 55% accuracy.
* 55 characters: Approximately 53% accuracy.
* 70 characters: Approximately 52% accuracy.
*Trend: Accuracy decreases with increasing character length.*
**DS-math-7b-instruct:**
* 0 characters: Approximately 40% accuracy.
* 10 characters: Approximately 40% accuracy.
* 25 characters: Approximately 41% accuracy.
* 40 characters: Approximately 41% accuracy.
* 55 characters: Approximately 40% accuracy.
* 70 characters: Approximately 40% accuracy.
*Trend: Relatively stable accuracy across character lengths.*
### Key Observations
* Qwen-2.5-MATH-7B and GPT-4o-mini consistently achieve the highest accuracy scores across most character lengths.
* The accuracy of GPT-4o-mini decreases noticeably as the character length increases.
* DS-math-7b-instruct consistently has the lowest accuracy scores.
* The impact of character length on accuracy varies between models. Some models are relatively unaffected, while others show a clear decline in performance with longer inputs.
### Interpretation
The chart demonstrates the performance of different language models on a mathematical reasoning task (MATH-500) as a function of input length. The varying performance suggests that the models have different capacities for handling longer and more complex inputs. The decrease in accuracy for GPT-4o-mini with increasing character length could indicate a limitation in its context window or its ability to process longer sequences effectively. The consistently lower performance of DS-math-7b-instruct suggests that it may be less capable in mathematical reasoning compared to the other models tested. The relatively stable performance of Qwen-2.5-MATH-7B across different character lengths suggests a robust ability to handle varying input complexities. This data is valuable for understanding the strengths and weaknesses of each model and for selecting the most appropriate model for a given task based on the expected input length and complexity.