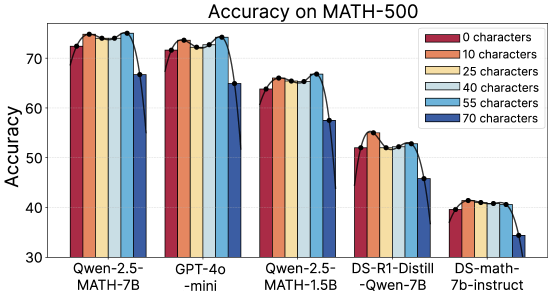
## Bar Chart: Accuracy on MATH-500
### Overview
This is a grouped bar chart comparing the performance (accuracy) of five different AI models on the MATH-500 benchmark. Performance is measured across six different input lengths, defined by the number of characters. The chart demonstrates how model accuracy varies with both the model architecture and the length of the input prompt.
### Components/Axes
* **Chart Title:** "Accuracy on MATH-500" (centered at the top).
* **Y-Axis:**
* **Label:** "Accuracy" (rotated vertically on the left).
* **Scale:** Linear scale from 30 to 70, with major tick marks at 30, 40, 50, 60, and 70.
* **X-Axis:**
* **Label:** None explicit. The axis displays categorical labels for five distinct AI models.
* **Categories (from left to right):**
1. `Qwen-2.5-MATH-7B`
2. `GPT-4o-mini`
3. `Qwen-2.5-MATH-1.5B`
4. `DS-R1-Distill-Qwen-7B`
5. `DS-math-7b-instruct`
* **Legend:**
* **Location:** Top-right corner of the chart area.
* **Title:** None.
* **Categories & Colors (from top to bottom):**
1. `0 characters` - Dark Red/Maroon
2. `10 characters` - Orange
3. `25 characters` - Light Yellow/Beige
4. `40 characters` - Light Blue
5. `55 characters` - Medium Blue
6. `70 characters` - Dark Blue
### Detailed Analysis
The chart presents accuracy percentages for each model across the six character-length conditions. Values are approximate based on visual bar height.
**1. Qwen-2.5-MATH-7B (Leftmost Group):**
* **Trend:** High and relatively stable accuracy for 0-55 characters, with a noticeable drop for 70 characters.
* **Approximate Values:**
* 0 chars (Dark Red): ~72%
* 10 chars (Orange): ~74%
* 25 chars (Yellow): ~74%
* 40 chars (Light Blue): ~74%
* 55 chars (Medium Blue): ~75%
* 70 chars (Dark Blue): ~67%
**2. GPT-4o-mini (Second Group):**
* **Trend:** Similar pattern to the first model—high accuracy for shorter inputs, with a drop at 70 characters.
* **Approximate Values:**
* 0 chars: ~72%
* 10 chars: ~73%
* 25 chars: ~73%
* 40 chars: ~74%
* 55 chars: ~75%
* 70 chars: ~65%
**3. Qwen-2.5-MATH-1.5B (Third Group):**
* **Trend:** Overall lower accuracy than the first two models. Shows a slight peak at 10/40/55 characters and a clear drop at 70 characters.
* **Approximate Values:**
* 0 chars: ~64%
* 10 chars: ~66%
* 25 chars: ~65%
* 40 chars: ~66%
* 55 chars: ~67%
* 70 chars: ~58%
**4. DS-R1-Distill-Qwen-7B (Fourth Group):**
* **Trend:** Significantly lower accuracy than the top three models. Peaks at 10 characters, then shows a general downward trend with increasing length.
* **Approximate Values:**
* 0 chars: ~52%
* 10 chars: ~55%
* 25 chars: ~53%
* 40 chars: ~53%
* 55 chars: ~53%
* 70 chars: ~46%
**5. DS-math-7b-instruct (Rightmost Group):**
* **Trend:** The lowest-performing model overall. Accuracy is relatively flat for 0-55 characters (around 40%) and drops for 70 characters.
* **Approximate Values:**
* 0 chars: ~40%
* 10 chars: ~41%
* 25 chars: ~41%
* 40 chars: ~41%
* 55 chars: ~40%
* 70 chars: ~35%
### Key Observations
1. **Performance Hierarchy:** There is a clear performance tier. `Qwen-2.5-MATH-7B` and `GPT-4o-mini` are the top performers, followed by `Qwen-2.5-MATH-1.5B`. The two "DS" models perform substantially worse.
2. **Impact of Input Length:** For all models, accuracy is generally highest for inputs between 10 and 55 characters. There is a consistent and notable drop in accuracy for the longest input length tested (70 characters).
3. **Optimal Length:** For most models, the 10-character condition often yields slightly higher accuracy than the 0-character (baseline) condition, suggesting a potential "sweet spot" for prompt length.
4. **Model Size vs. Performance:** The smaller `Qwen-2.5-MATH-1.5B` model underperforms its 7B counterpart, as expected. However, the `DS-R1-Distill-Qwen-7B` model, despite having 7B parameters, performs worse than the smaller Qwen model, indicating that architecture or training method is a critical factor beyond sheer size.
### Interpretation
The data suggests two primary findings:
1. **Input Length Sensitivity:** All evaluated models exhibit sensitivity to the length of the input prompt, with a performance degradation occurring at the longest length (70 characters). This could be due to increased complexity, longer-range dependencies in the problem statement, or limitations in the models' context handling for this specific task. The drop is most pronounced for the top-performing models in absolute terms.
2. **Model Efficacy on Mathematical Reasoning:** The chart clearly separates models based on their specialized training for mathematical tasks. The `Qwen-2.5-MATH` series and `GPT-4o-mini` demonstrate strong performance, indicating effective training on mathematical data. In contrast, the "DS" models (likely from a different provider or training paradigm) show significantly lower accuracy, highlighting that general language model capability does not automatically translate to strong mathematical reasoning performance. The fact that `DS-R1-Distill-Qwen-7B` underperforms the smaller `Qwen-2.5-MATH-1.5B` strongly supports the importance of specialized fine-tuning or distillation for this domain.
**In summary, the chart provides evidence that for the MATH-500 benchmark, model choice is the dominant factor in accuracy, but input length is a significant secondary factor, with a consistent negative impact at the longest tested length.**