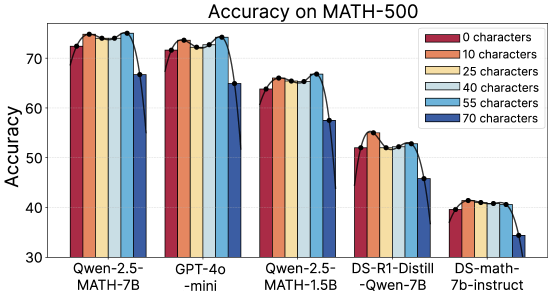
## Bar Chart: Accuracy on MATH-500
### Overview
The chart compares the accuracy of five AI models (Qwen-2.5-MATH-7B, GPT-4o-mini, Qwen-2.5-MATH-1.5B, DS-R1-Distill-Qwen-7B, DS-math-7b-instruct) on the MATH-500 benchmark across six input complexity levels (0, 10, 25, 40, 55, 70 characters). Accuracy is measured on a 0-100% scale.
### Components/Axes
- **X-axis**: Model names (Qwen-2.5-MATH-7B, GPT-4o-mini, Qwen-2.5-MATH-1.5B, DS-R1-Distill-Qwen-7B, DS-math-7b-instruct)
- **Y-axis**: Accuracy percentage (30-70% range)
- **Legend**: Located in the top-right corner, mapping colors to character counts:
- Red: 0 characters
- Orange: 10 characters
- Yellow: 25 characters
- Light blue: 40 characters
- Dark blue: 55 characters
- Darkest blue: 70 characters
### Detailed Analysis
1. **Qwen-2.5-MATH-7B**:
- Accuracy: 73% (0 chars) → 74% (10 chars) → 73% (25 chars) → 72% (40 chars) → 71% (55 chars) → 67% (70 chars)
- Trend: Gradual decline with increasing complexity
2. **GPT-4o-mini**:
- Accuracy: 72% (0 chars) → 73% (10 chars) → 72% (25 chars) → 71% (40 chars) → 70% (55 chars) → 65% (70 chars)
- Trend: Slightly steeper decline than Qwen-2.5-MATH-7B
3. **Qwen-2.5-MATH-1.5B**:
- Accuracy: 65% (0 chars) → 66% (10 chars) → 65% (25 chars) → 64% (40 chars) → 63% (55 chars) → 58% (70 chars)
- Trend: More pronounced drop at higher complexities
4. **DS-R1-Distill-Qwen-7B**:
- Accuracy: 53% (0 chars) → 54% (10 chars) → 53% (25 chars) → 52% (40 chars) → 51% (55 chars) → 46% (70 chars)
- Trend: Consistent decline with complexity
5. **DS-math-7b-instruct**:
- Accuracy: 40% (0 chars) → 41% (10 chars) → 40% (25 chars) → 40% (40 chars) → 39% (55 chars) → 34% (70 chars)
- Trend: Sharpest decline among all models
### Key Observations
- **Model Capacity Correlation**: Larger models (Qwen-2.5-MATH-7B, GPT-4o-mini) maintain higher baseline accuracy (70-74%) compared to smaller models (DS-math-7b-instruct at 40% baseline).
- **Complexity Sensitivity**: All models show reduced accuracy with increased input complexity, but smaller models experience steeper declines (DS-math-7b-instruct drops 6 percentage points from 0 to 70 chars).
- **Stability Patterns**: Qwen-2.5-MATH-7B demonstrates the most stable performance across complexities (only 7% drop from 0 to 70 chars).
### Interpretation
The data reveals a clear relationship between model size and robustness to input complexity. Larger models maintain higher accuracy even with complex inputs, suggesting superior capacity to handle nuanced mathematical reasoning. The consistent downward trend across all models indicates that character count is a significant factor in performance on MATH-500, potentially reflecting increased cognitive load or contextual dependency in longer problems. Notably, the DS-math-7b-instruct model's performance suggests that even base models can achieve moderate accuracy on simpler problems, but struggle significantly with more complex inputs. This pattern underscores the importance of model architecture and training data quality in mathematical reasoning tasks.