## Bar Chart: Model Strength Comparison
### Overview
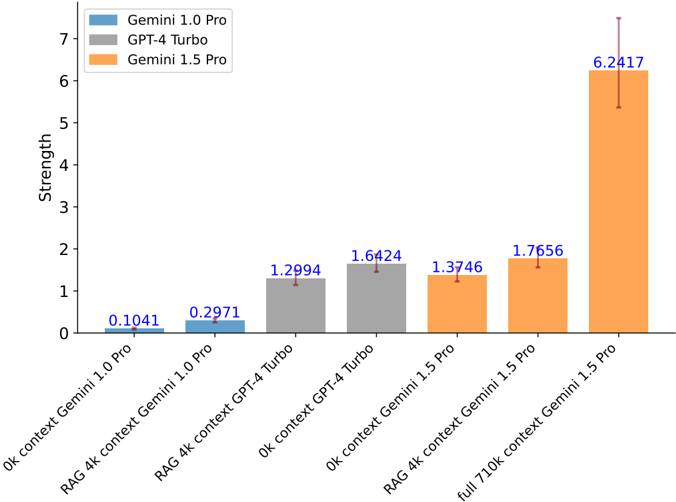
The image is a bar chart comparing the "Strength" of three different language models (Gemini 1.0 Pro, GPT-4 Turbo, and Gemini 1.5 Pro) under various context conditions. The y-axis represents "Strength," and the x-axis represents the different context scenarios for each model. Error bars are present on each bar, indicating the uncertainty in the strength measurement.
### Components/Axes
* **Y-axis:** "Strength," with a numerical scale from 0 to 7.
* **X-axis:** Categorical axis representing different models and context scenarios. The labels are rotated for readability.
* **Legend (Top-Left):**
* Blue: Gemini 1.0 Pro
* Gray: GPT-4 Turbo
* Orange: Gemini 1.5 Pro
* **Error Bars:** Represented as thin vertical lines extending above and below the top of each bar.
### Detailed Analysis
The chart compares the strength of three language models under different context conditions.
* **Gemini 1.0 Pro (Blue):**
* "0k context Gemini 1.0 Pro": Strength = 0.1041
* "RAG 4k context Gemini 1.0 Pro": Strength = 0.2971
* Trend: The strength increases with the addition of RAG 4k context.
* **GPT-4 Turbo (Gray):**
* "0k context GPT-4 Turbo": Strength = 1.2994
* "RAG 4k context GPT-4 Turbo": Strength = 1.6424
* Trend: The strength increases with the addition of RAG 4k context.
* **Gemini 1.5 Pro (Orange):**
* "0k context Gemini 1.5 Pro": Strength = 1.3746
* "RAG 4k context Gemini 1.5 Pro": Strength = 1.7656
* "full 710k context Gemini 1.5 Pro": Strength = 6.2417
* Trend: The strength increases with the addition of RAG 4k context, and significantly increases with a full 710k context.
### Key Observations
* Gemini 1.5 Pro with "full 710k context" has significantly higher strength compared to all other models and context conditions.
* For all models, adding "RAG 4k context" improves the strength compared to "0k context."
* GPT-4 Turbo consistently shows higher strength than Gemini 1.0 Pro under similar context conditions.
### Interpretation
The data suggests that context plays a crucial role in the performance ("Strength") of language models. The Gemini 1.5 Pro model, when provided with a large "full 710k context," demonstrates a substantial increase in strength, indicating its ability to leverage extensive context effectively. The RAG (Retrieval-Augmented Generation) 4k context also improves the strength of all models, suggesting that incorporating retrieved information enhances their performance. The difference in strength between GPT-4 Turbo and Gemini 1.0 Pro under similar conditions may reflect differences in their architectures or training data. The error bars indicate the variability in the strength measurements, which should be considered when interpreting the results.