\n
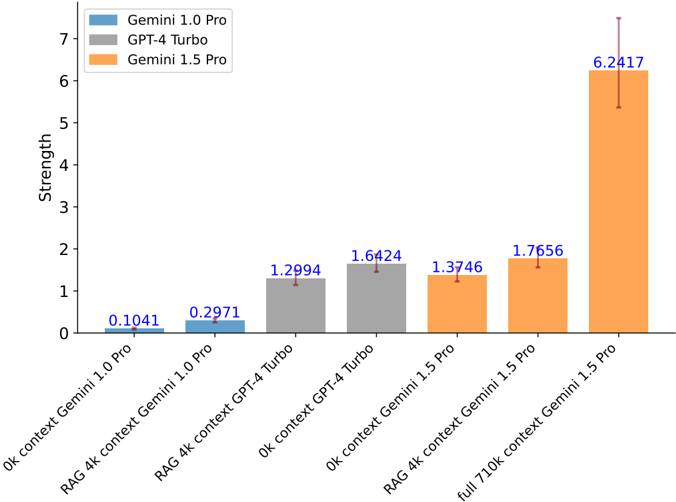
## Bar Chart: Model Performance Comparison
### Overview
This bar chart compares the performance "Strength" of three large language models – Gemini 1.0 Pro, GPT-4 Turbo, and Gemini 1.5 Pro – across different context lengths and retrieval augmented generation (RAG) scenarios. The chart uses bar height to represent the "Strength" metric, with error bars indicating variability.
### Components/Axes
* **X-axis:** Represents the different testing conditions. The categories are: "Ok context Gemini 1.0 Pro", "RAG 4k context Gemini 1.0 Pro", "RAG 4k context GPT-4 Turbo", "Ok context GPT-4 Turbo", "Ok context Gemini 1.5 Pro", "RAG 4k context Gemini 1.5 Pro", and "full 710k context Gemini 1.5 Pro".
* **Y-axis:** Labeled "Strength", with a scale ranging from 0 to 7, incrementing by 1.
* **Legend:** Located in the top-left corner, identifying the colors associated with each model:
* Gemini 1.0 Pro: Light Blue
* GPT-4 Turbo: Gray
* Gemini 1.5 Pro: Orange
### Detailed Analysis
The chart displays the "Strength" values for each model under each condition. Error bars are present for the Gemini 1.5 Pro data points.
* **Gemini 1.0 Pro:**
* "Ok context": Approximately 0.1041. The bar is light blue.
* "RAG 4k context": Approximately 0.2971. The bar is light blue.
* **GPT-4 Turbo:**
* "Ok context": Approximately 1.2994. The bar is gray.
* "RAG 4k context": Approximately 1.6424. The bar is gray.
* **Gemini 1.5 Pro:**
* "Ok context": Approximately 1.3746. The bar is orange.
* "RAG 4k context": Approximately 1.7656. The bar is orange.
* "full 710k context": Approximately 6.2417, with an error bar extending to approximately 6.8. The bar is orange.
The error bar for the "full 710k context Gemini 1.5 Pro" data point extends upwards, indicating a significant degree of variability in the results.
### Key Observations
* Gemini 1.5 Pro consistently outperforms Gemini 1.0 Pro and GPT-4 Turbo in all tested conditions.
* The largest performance gain for Gemini 1.5 Pro is observed when using the full 710k context window, showing a substantial increase in "Strength" compared to the other conditions.
* GPT-4 Turbo shows a slight performance improvement when using RAG 4k context compared to "Ok context".
* Gemini 1.0 Pro has the lowest "Strength" values across all conditions.
### Interpretation
The data suggests that Gemini 1.5 Pro is significantly more capable than both Gemini 1.0 Pro and GPT-4 Turbo, particularly when leveraging its extended context window. The substantial increase in "Strength" with the 710k context window indicates that Gemini 1.5 Pro can effectively utilize a larger amount of information to improve its performance. The error bar on the 710k context data point suggests that the performance can vary, potentially due to the complexity of processing such a large context. The RAG implementation appears to provide a modest performance boost for both Gemini 1.0 Pro and GPT-4 Turbo, but the effect is less pronounced than the impact of the larger context window for Gemini 1.5 Pro. This chart demonstrates the importance of context length in the performance of large language models, and highlights Gemini 1.5 Pro's advantage in this area.