## Bar Chart: AI Model Strength Comparison Across Context Configurations
### Overview
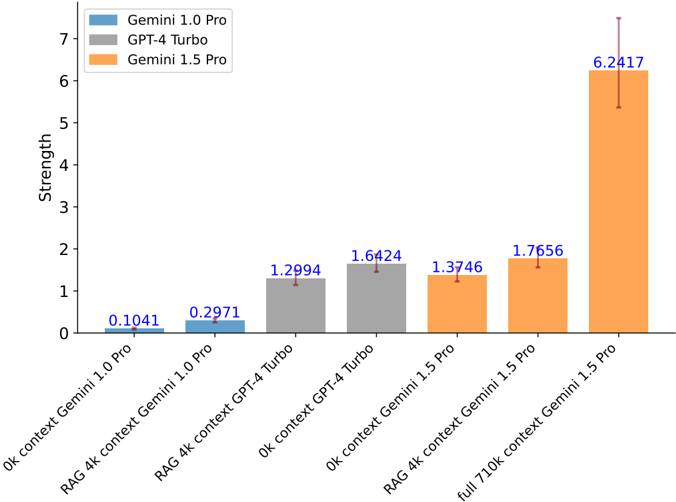
The image is a vertical bar chart comparing the "Strength" metric of three large language models (Gemini 1.0 Pro, GPT-4 Turbo, Gemini 1.5 Pro) under different context window and Retrieval-Augmented Generation (RAG) configurations. The chart demonstrates a clear performance hierarchy and the significant impact of context size on the latest model.
### Components/Axes
* **Chart Type:** Grouped bar chart with error bars.
* **Y-Axis:**
* **Label:** "Strength"
* **Scale:** Linear, ranging from 0 to 7, with major tick marks at every integer.
* **X-Axis:**
* **Labels (from left to right):**
1. `0k context Gemini 1.0 Pro`
2. `RAG 4k context Gemini 1.0 Pro`
3. `RAG 4k context GPT-4 Turbo`
4. `0k context GPT-4 Turbo`
5. `0k context Gemini 1.5 Pro`
6. `RAG 4k context Gemini 1.5 Pro`
7. `full 710k context Gemini 1.5 Pro`
* **Legend:** Located in the top-left corner of the plot area.
* **Blue Square:** `Gemini 1.0 Pro`
* **Gray Square:** `GPT-4 Turbo`
* **Orange Square:** `Gemini 1.5 Pro`
* **Data Labels:** Each bar has its precise numerical value displayed directly above it in blue text.
* **Error Bars:** Each bar includes a vertical error bar (whisker) indicating variability or confidence intervals around the mean value.
### Detailed Analysis
The chart presents seven distinct data points, grouped by model and configuration:
1. **Gemini 1.0 Pro (Blue Bars):**
* **0k context:** Strength = **0.1041**. Very low performance with no context.
* **RAG 4k context:** Strength = **0.2971**. A modest improvement with RAG and a 4k context window.
2. **GPT-4 Turbo (Gray Bars):**
* **RAG 4k context:** Strength = **1.2994**.
* **0k context:** Strength = **1.6424**. Notably, the 0k context performance is higher than the RAG 4k context performance for this model in this specific benchmark.
3. **Gemini 1.5 Pro (Orange Bars):**
* **0k context:** Strength = **1.3746**. Performs comparably to GPT-4 Turbo's 0k context result.
* **RAG 4k context:** Strength = **1.7656**. Shows a clear improvement over its 0k context baseline.
* **full 710k context:** Strength = **6.2417**. This is the most striking data point, showing a massive, disproportionate increase in strength when utilizing the model's full native context window. The error bar for this point is also the largest, spanning approximately from 5.4 to 7.1.
**Trend Verification:**
* **Gemini 1.0 Pro (Blue):** The line of bars slopes gently upward from left to right, showing a small positive effect from adding RAG.
* **GPT-4 Turbo (Gray):** The two bars are at a moderate height, with the right bar (0k context) being slightly taller than the left (RAG 4k).
* **Gemini 1.5 Pro (Orange):** The series shows a clear, steep upward trend. The first two bars (0k and RAG 4k) are moderately tall, while the third bar (full 710k context) is dramatically taller, creating a sharp positive slope.
### Key Observations
1. **Dominant Outlier:** The `full 710k context Gemini 1.5 Pro` configuration is a significant outlier, with a strength value (6.2417) more than 3.5 times higher than the next closest configuration (RAG 4k context Gemini 1.5 Pro at 1.7656).
2. **Model Generational Leap:** Gemini 1.5 Pro (orange) consistently outperforms Gemini 1.0 Pro (blue) in comparable configurations (0k and RAG 4k), indicating a major generational improvement.
3. **Context vs. RAG for GPT-4 Turbo:** For GPT-4 Turbo, the `0k context` setup yields a higher score than the `RAG 4k context` setup, which is an unexpected result that may be specific to the evaluation methodology.
4. **Error Bar Correlation:** The size of the error bars generally increases with the mean strength value, with the highest-value bar also having the largest absolute uncertainty.
### Interpretation
This chart provides a compelling technical demonstration of the relationship between model architecture, context window size, and performance on a specific (though unnamed) "Strength" benchmark.
* **The Power of Native Context:** The most profound finding is that Gemini 1.5 Pro's performance is not linearly improved by adding external RAG (a 4k boost), but is **exponentially enhanced** by leveraging its massive native 710k token context window. This suggests the model can effectively utilize and reason over vast amounts of in-context information in a way that fundamentally changes its capabilities for this task, surpassing the gains from retrieval augmentation alone.
* **Benchmark Specificity:** The anomaly with GPT-4 Turbo (0k > RAG 4k) hints that the "Strength" metric may be sensitive to the specific retrieval process or that the model's zero-shot capability is particularly strong for this task. It underscores that RAG is not a universal performance enhancer.
* **Evolution of Capabilities:** The progression from Gemini 1.0 to 1.5 shows that architectural advancements have yielded greater performance gains than simply applying RAG to an older model. The full-context capability of the newer model represents a different class of performance altogether.
In summary, the data argues that for certain advanced models and tasks, scaling the native context window to extreme lengths (710k tokens) can be a more powerful performance driver than traditional RAG techniques with smaller windows, marking a potential paradigm shift in how we approach complex, information-dense problems with LLMs.