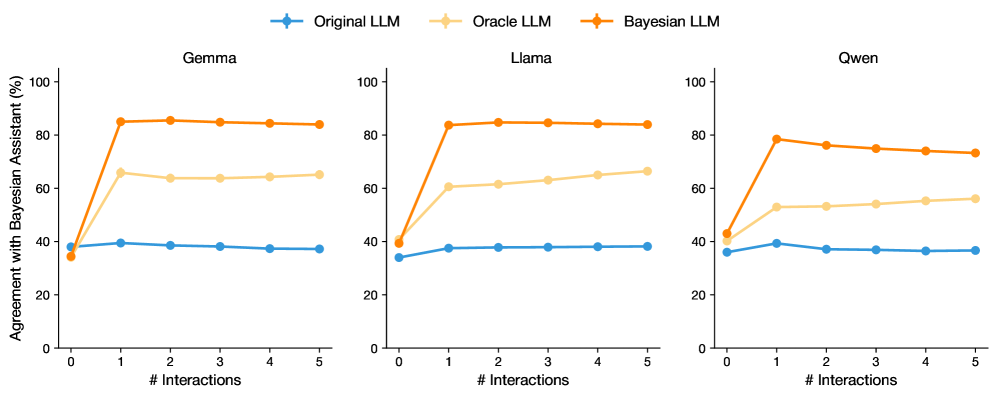
## Line Charts: Agreement with Bayesian Assistant vs. Number of Interactions
### Overview
This image presents three separate line charts, each comparing the agreement with a Bayesian Assistant (measured in percentage) for three different Large Language Models (LLMs): Gemma, Llama, and Qwen. The x-axis represents the number of interactions, ranging from 0 to 5, while the y-axis represents the percentage of agreement, ranging from 0% to 100%. Each chart displays three lines, each representing a different LLM configuration: Original LLM, Oracle LLM, and Bayesian LLM.
### Components/Axes
* **X-axis Title:** "# Interactions"
* **Y-axis Title:** "Agreement with Bayesian Assistant (%)"
* **Legend:** Located at the top-left of each chart.
* Original LLM (Blue line with triangle markers)
* Oracle LLM (Green line with circle markers)
* Bayesian LLM (Orange line with diamond markers)
* **Chart Titles:** Gemma, Llama, Qwen (positioned above each respective chart)
* **X-axis Markers:** 0, 1, 2, 3, 4, 5
* **Y-axis Markers:** 0, 20, 40, 60, 80, 100
### Detailed Analysis or Content Details
**Gemma Chart:**
* **Original LLM (Blue):** Starts at approximately 32% agreement at 0 interactions, fluctuates around 38-42% for interactions 1-4, and decreases to approximately 30% at 5 interactions.
* **Oracle LLM (Green):** Starts at approximately 58% agreement at 0 interactions, increases to around 65% at 1 interaction, then plateaus around 60-65% for interactions 2-5.
* **Bayesian LLM (Orange):** Starts at approximately 88% agreement at 0 interactions, decreases sharply to around 70% at 1 interaction, and then plateaus around 70-75% for interactions 2-5.
**Llama Chart:**
* **Original LLM (Blue):** Starts at approximately 32% agreement at 0 interactions, remains relatively stable around 38-42% for all interactions up to 5.
* **Oracle LLM (Green):** Starts at approximately 32% agreement at 0 interactions, increases rapidly to around 85% at 1 interaction, and then decreases slightly to around 80% for interactions 2-5.
* **Bayesian LLM (Orange):** Starts at approximately 32% agreement at 0 interactions, increases rapidly to around 88% at 1 interaction, and then decreases slightly to around 84% for interactions 2-5.
**Qwen Chart:**
* **Original LLM (Blue):** Starts at approximately 48% agreement at 0 interactions, decreases to around 32-38% for interactions 1-5.
* **Oracle LLM (Green):** Starts at approximately 48% agreement at 0 interactions, increases rapidly to around 80% at 1 interaction, and then decreases to around 65-70% for interactions 2-5.
* **Bayesian LLM (Orange):** Starts at approximately 88% agreement at 0 interactions, decreases rapidly to around 75% at 1 interaction, and then decreases to around 60-65% for interactions 2-5.
### Key Observations
* The Bayesian LLM consistently demonstrates the highest agreement with the Bayesian Assistant at 0 interactions across all three models.
* The Oracle LLM shows the most significant increase in agreement with the Bayesian Assistant after the first interaction across all three models.
* The Original LLM generally exhibits the lowest and most stable agreement with the Bayesian Assistant across all three models.
* Agreement with the Bayesian Assistant tends to decrease for the Bayesian and Oracle LLMs as the number of interactions increases, suggesting a potential diminishing return or adaptation effect.
### Interpretation
The data suggests that incorporating Bayesian principles (as seen in the Bayesian LLM) or oracle-based feedback (as seen in the Oracle LLM) can significantly improve the agreement of LLMs with a Bayesian Assistant, particularly at the start of an interaction sequence. The initial high agreement of the Bayesian LLM indicates that the Bayesian framework is effective in aligning the model's responses with the assistant's expectations. The rapid increase in agreement for the Oracle LLM suggests that providing feedback or guidance can quickly improve performance.
The decreasing agreement observed in the Bayesian and Oracle LLMs as the number of interactions increases could be due to several factors. It might indicate that the models are adapting to the interaction context and diverging from the initial Bayesian alignment, or that the feedback provided by the Bayesian Assistant becomes less relevant or effective over time. The relatively stable, lower agreement of the Original LLM suggests that it lacks the mechanisms to effectively incorporate Bayesian principles or feedback, resulting in consistent but suboptimal performance.
The differences between the models (Gemma, Llama, Qwen) highlight the varying capabilities of different LLM architectures in leveraging Bayesian approaches and feedback mechanisms. Further investigation is needed to understand the underlying reasons for these differences and to optimize the integration of Bayesian principles into LLMs for improved performance and alignment.