## Line Graphs: Reward Performance Across Learning Paradigms
### Overview
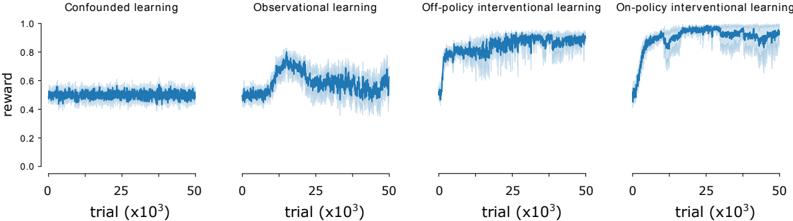
The image contains four line graphs comparing reward performance across different learning paradigms: Confounded learning, Observational learning, Off-policy interventional learning, and On-policy interventional learning. Each graph tracks reward values (0.0–1.0) over trials (0–50,000, scaled by 10³). Shaded regions around lines indicate variability.
### Components/Axes
- **X-axis**: Trial count (0 to 50,000, labeled as "trial (x10³)").
- **Y-axis**: Reward (0.0 to 1.0).
- **Legends**: Positioned at the top of each graph, matching line colors:
- Confounded learning: Dark blue.
- Observational learning: Medium blue.
- Off-policy interventional learning: Light blue.
- On-policy interventional learning: Dark blue (same as Confounded, but distinct line style).
- **Shading**: Gray bands around lines represent variability (approximate ±0.1–0.15 range).
### Detailed Analysis
1. **Confounded learning**:
- Reward remains flat at ~0.5 throughout trials.
- Variability: ±0.05–0.1 (shaded region).
- No significant trend observed.
2. **Observational learning**:
- Initial reward ~0.5, peaks at ~0.7 (trial ~12,500), then declines to ~0.6.
- Variability: ±0.05–0.1.
- Slight upward trend in early trials, followed by stabilization.
3. **Off-policy interventional learning**:
- Sharp increase from ~0.5 to ~0.8 (trial ~12,500), then stabilizes.
- Variability: ±0.05–0.1.
- Sustained high performance after initial rise.
4. **On-policy interventional learning**:
- Steep rise from ~0.5 to ~0.9 (trial ~12,500), then plateaus.
- Variability: ±0.05–0.1.
- Highest final reward (~0.9) among all paradigms.
### Key Observations
- **On-policy interventional learning** achieves the highest reward (~0.9), outperforming all other methods.
- **Off-policy interventional learning** shows a significant improvement (~0.8) but lags behind on-policy.
- **Observational learning** exhibits a temporary peak but underperforms compared to interventional methods.
- **Confounded learning** remains the least effective, with no improvement over trials.
### Interpretation
The data suggests that **interventional learning paradigms** (both on-policy and off-policy) outperform observational and confounded learning. On-policy interventional learning demonstrates the strongest performance, likely due to direct policy adjustments during training. Off-policy methods show promise but may lack real-time feedback. Observational learning’s decline after an initial peak could indicate overfitting or insufficient exploration. Confounded learning’s stagnation highlights the limitations of unstructured or biased data environments. The shaded variability bands suggest all methods have inherent instability, but interventional approaches maintain tighter performance bounds after initial adaptation.