## Flowchart: Model Solving FrontierMath Problems
### Overview
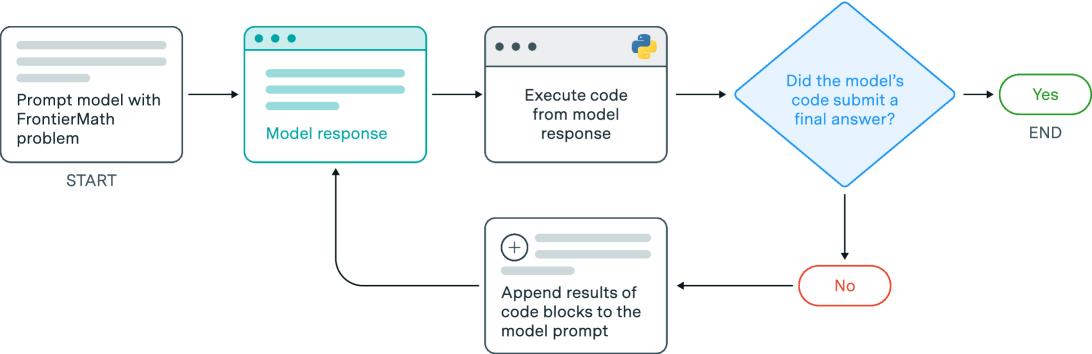
The image is a flowchart illustrating the process of a model solving FrontierMath problems. It shows the steps involved, from prompting the model to determining if the model's code submitted a final answer. The flowchart includes decision points and loops, indicating an iterative process.
### Components/Axes
The flowchart consists of the following components:
* **Start:** Labeled "START", indicates the beginning of the process.
* **Prompt model with FrontierMath problem:** A rectangular box representing the initial step of providing the model with a problem.
* **Model response:** A rectangular box representing the model's response to the prompt.
* **Execute code from model response:** A rectangular box representing the execution of code generated by the model. A Python logo is present in the top right corner of this box.
* **Did the model's code submit a final answer?:** A diamond shape representing a decision point.
* **Yes:** A rounded rectangle indicating the successful completion of the process, labeled "END".
* **No:** A rounded rectangle indicating that the model's code did not submit a final answer.
* **Append results of code blocks to the model prompt:** A rectangular box representing the step of appending the results of code blocks to the model prompt.
* **Arrows:** Arrows indicate the flow of the process.
### Detailed Analysis or ### Content Details
1. **START:** The process begins with "Prompt model with FrontierMath problem".
2. The model generates a "Model response".
3. The code from the model's response is executed ("Execute code from model response").
4. A decision is made: "Did the model's code submit a final answer?".
* If "Yes", the process ends ("END").
* If "No", the results of the code blocks are appended to the model prompt ("Append results of code blocks to the model prompt"), and the process loops back to the "Model response" step.
### Key Observations
* The flowchart illustrates an iterative process where the model refines its response based on the results of executed code.
* The Python logo suggests that the code being executed is likely Python code.
* The "No" path creates a feedback loop, allowing the model to improve its answer.
### Interpretation
The flowchart describes a system where a model attempts to solve FrontierMath problems by generating and executing code. If the initial code execution does not produce a final answer, the results are fed back into the model to refine its approach. This iterative process continues until the model successfully submits a final answer. The use of Python suggests a specific implementation environment for the code execution. The diagram highlights the importance of feedback loops in complex problem-solving scenarios.