## Bar Chart: Verifier performance on ProcessBench
### Overview
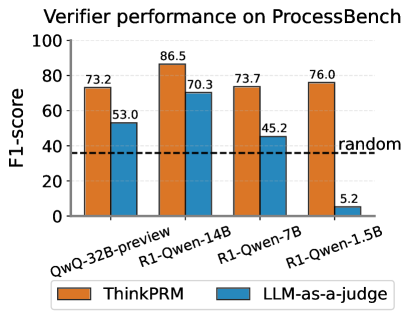
The image is a bar chart comparing the F1-score performance of two verifiers, "ThinkPRM" and "LLM-as-a-judge," on the ProcessBench dataset. The x-axis represents different model configurations (QwQ-32B-preview, R1-Qwen-14B, R1-Qwen-7B, R1-Qwen-1.5B), and the y-axis represents the F1-score, ranging from 0 to 100. A horizontal dashed line indicates a "random" baseline performance.
### Components/Axes
* **Title:** Verifier performance on ProcessBench
* **X-axis:** Model configurations: QwQ-32B-preview, R1-Qwen-14B, R1-Qwen-7B, R1-Qwen-1.5B
* **Y-axis:** F1-score, ranging from 0 to 100, with tick marks at intervals of 20.
* **Legend:** Located at the bottom of the chart.
* Orange bars: ThinkPRM
* Blue bars: LLM-as-a-judge
* **Horizontal Dashed Line:** Labeled "random"
### Detailed Analysis
The chart presents F1-scores for each model configuration, comparing ThinkPRM (orange bars) and LLM-as-a-judge (blue bars).
* **QwQ-32B-preview:**
* ThinkPRM: 73.2
* LLM-as-a-judge: 53.0
* **R1-Qwen-14B:**
* ThinkPRM: 86.5
* LLM-as-a-judge: 70.3
* **R1-Qwen-7B:**
* ThinkPRM: 73.7
* LLM-as-a-judge: 45.2
* **R1-Qwen-1.5B:**
* ThinkPRM: 76.0
* LLM-as-a-judge: 5.2
### Key Observations
* ThinkPRM consistently outperforms LLM-as-a-judge across all model configurations except for R1-Qwen-1.5B, where LLM-as-a-judge performs significantly worse.
* The performance of LLM-as-a-judge drops drastically with the R1-Qwen-1.5B model.
* R1-Qwen-14B achieves the highest F1-score for ThinkPRM (86.5).
### Interpretation
The data suggests that ThinkPRM is a more effective verifier than LLM-as-a-judge for most model configurations tested on the ProcessBench dataset. The significant drop in performance of LLM-as-a-judge with the R1-Qwen-1.5B model indicates a potential limitation or incompatibility with smaller models. The "random" baseline provides a reference point, showing that all configurations except LLM-as-a-judge with R1-Qwen-1.5B perform significantly better than random chance. The R1-Qwen-14B model appears to be the most effective configuration for ThinkPRM within this set of experiments.