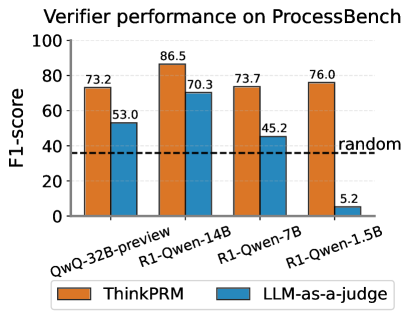
## Bar Chart: Verifier Performance on ProcessBench
### Overview
This bar chart displays the F1-score performance of two verifiers, "ThinkPRM" and "LLMs-as-a-judge", across four different models: QwQ-32B-preview, R1-Qwen-14B, R1-Qwen-7B, and R1-Qwen-1.5B. A horizontal dashed line indicates the performance of a "random" verifier, serving as a baseline.
### Components/Axes
* **Title:** "Verifier performance on ProcessBench" (top-center)
* **Y-axis:** "F1-score" (left-side, ranging from 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100)
* **X-axis:** Model names: "QwQ-32B-preview", "R1-Qwen-14B", "R1-Qwen-7B", "R1-Qwen-1.5B" (bottom-center)
* **Legend:** Located at the bottom-center.
* Orange: "ThinkPRM"
* Blue: "LLMs-as-a-judge"
* **Baseline:** A horizontal dashed line labeled "random" at an F1-score of approximately 40.
### Detailed Analysis
The chart consists of paired bars for each model, representing the F1-scores of "ThinkPRM" and "LLMs-as-a-judge".
* **QwQ-32B-preview:**
* ThinkPRM: Approximately 73.2 F1-score. (Orange bar)
* LLMs-as-a-judge: Approximately 53.0 F1-score. (Blue bar)
* **R1-Qwen-14B:**
* ThinkPRM: Approximately 86.5 F1-score. (Orange bar) - Highest score for ThinkPRM.
* LLMs-as-a-judge: Approximately 70.3 F1-score. (Blue bar)
* **R1-Qwen-7B:**
* ThinkPRM: Approximately 73.7 F1-score. (Orange bar)
* LLMs-as-a-judge: Approximately 45.2 F1-score. (Blue bar)
* **R1-Qwen-1.5B:**
* ThinkPRM: Approximately 76.0 F1-score. (Orange bar)
* LLMs-as-a-judge: Approximately 5.2 F1-score. (Blue bar) - Lowest score for LLMs-as-a-judge.
The "random" baseline is a horizontal dashed line at approximately 40 F1-score.
### Key Observations
* "ThinkPRM" consistently outperforms "LLMs-as-a-judge" across all models.
* The highest performance for "ThinkPRM" is achieved with the "R1-Qwen-14B" model (86.5 F1-score).
* "LLMs-as-a-judge" shows a significant drop in performance with the "R1-Qwen-1.5B" model (5.2 F1-score), falling well below the random baseline.
* Both verifiers perform above the random baseline for the QwQ-32B-preview, R1-Qwen-14B, and R1-Qwen-7B models.
### Interpretation
The data suggests that "ThinkPRM" is a more reliable verifier than "LLMs-as-a-judge" on the ProcessBench dataset. The performance of "LLMs-as-a-judge" is particularly sensitive to the underlying model, with a drastic decrease in F1-score when used with "R1-Qwen-1.5B". This could indicate that "LLMs-as-a-judge" requires larger or more complex models to achieve acceptable performance. The random baseline provides a crucial point of reference, highlighting that both verifiers offer value beyond random chance, except for the "LLMs-as-a-judge" with the "R1-Qwen-1.5B" model. The consistent outperformance of "ThinkPRM" suggests it may be a more robust and generalizable verifier across different model architectures. The chart demonstrates the importance of evaluating verifiers on a variety of models to understand their limitations and strengths.