## Bar Chart: Verifier performance on ProcessBench
### Overview
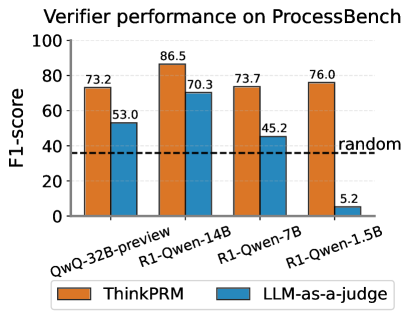
The chart compares the F1-score performance of two verification methods ("ThinkPRM" and "LLM-as-a-judge") across four language models (QwQ-32B-preview, R1-Qwen-14B, R1-Qwen-7B, R1-Qwen-1.5B) on the ProcessBench benchmark. A dashed "random" baseline at 40 F1-score is included for reference.
### Components/Axes
- **X-axis**: Language models (categorical):
QwQ-32B-preview | R1-Qwen-14B | R1-Qwen-7B | R1-Qwen-1.5B
- **Y-axis**: F1-score (continuous, 0–100)
- **Legend**:
- Orange: ThinkPRM
- Blue: LLM-as-a-judge
- **Additional element**: Dashed black line labeled "random" at 40 F1-score
### Detailed Analysis
- **QwQ-32B-preview**:
- ThinkPRM: 73.2 (orange bar)
- LLM-as-a-judge: 53.0 (blue bar)
- **R1-Qwen-14B**:
- ThinkPRM: 86.5 (orange bar)
- LLM-as-a-judge: 70.3 (blue bar)
- **R1-Qwen-7B**:
- ThinkPRM: 73.7 (orange bar)
- LLM-as-a-judge: 45.2 (blue bar)
- **R1-Qwen-1.5B**:
- ThinkPRM: 76.0 (orange bar)
- LLM-as-a-judge: 5.2 (blue bar)
### Key Observations
1. **ThinkPRM consistently outperforms LLM-as-a-judge** across all models, with F1-scores ranging from 73.2 to 86.5 (vs. 5.2 to 70.3).
2. **R1-Qwen-14B** achieves the highest performance for both methods (86.5 for ThinkPRM, 70.3 for LLM-as-a-judge).
3. **R1-Qwen-1.5B** shows a drastic drop for LLM-as-a-judge (5.2), falling below the "random" baseline (40).
4. **LLM-as-a-judge** scores decline sharply for smaller models (e.g., 45.2 for R1-Qwen-7B vs. 70.3 for R1-Qwen-14B).
### Interpretation
- **ThinkPRM's robustness**: Its performance remains stable across models, suggesting it is less sensitive to model size or architecture.
- **LLM-as-a-judge's limitations**: Its performance correlates with model size, performing poorly on smaller models (e.g., R1-Qwen-1.5B). This may indicate reliance on larger model capacity for effective judgment.
- **Random baseline**: The "random" line at 40 F1-score highlights that even the worst LLM-as-a-judge (5.2) barely exceeds random guessing, raising questions about its reliability for smaller models.
- **Implications**: ThinkPRM may be preferable for verification tasks, especially when working with smaller language models where LLM-as-a-judge underperforms.