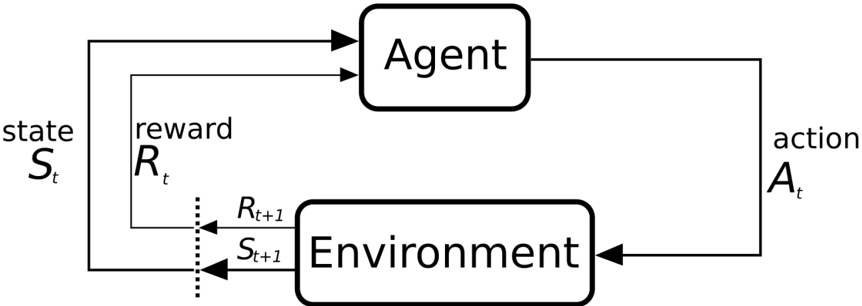
## Diagram: Reinforcement Learning Agent-Environment Interaction Loop
### Overview
The image is a black-and-white schematic diagram illustrating the fundamental interaction cycle in a reinforcement learning (RL) framework. It depicts the continuous feedback loop between a decision-making "Agent" and its "Environment," showing the flow of states, actions, and rewards over discrete time steps.
### Components/Axes
The diagram consists of two primary rectangular boxes with rounded corners and several labeled arrows indicating directional flow.
1. **Main Components:**
* **Agent:** A box located in the upper-center of the diagram.
* **Environment:** A box located in the lower-center of the diagram.
2. **Flow Labels and Symbols:**
* **`state S_t`**: Text label on the left side, with an arrow pointing from the Environment box to the Agent box. The symbol `S_t` denotes the state at time step `t`.
* **`reward R_t`**: Text label positioned just above the `state S_t` label, with an arrow pointing from the Environment box to the Agent box. The symbol `R_t` denotes the reward received at time step `t`.
* **`action A_t`**: Text label on the right side, with an arrow pointing from the Agent box to the Environment box. The symbol `A_t` denotes the action taken at time step `t`.
* **`R_{t+1}` and `S_{t+1}`**: These symbols are placed near the output of the Environment box, to the left of it. They are connected by a vertical dotted line, indicating they are the outputs of the Environment for the next time step (`t+1`).
* **Directional Arrows:** Solid black arrows clearly define the flow of information:
* From Environment to Agent: Carries `S_t` and `R_t`.
* From Agent to Environment: Carries `A_t`.
* From Environment back to the start of the loop: Carries `S_{t+1}` and `R_{t+1}`.
### Detailed Analysis
The diagram explicitly maps the sequential, cyclical process of reinforcement learning:
1. At time step `t`, the **Environment** is in a state `S_t` and provides this state information, along with a reward signal `R_t`, to the **Agent**.
2. The **Agent** receives `S_t` and `R_t`. Based on this input (and its internal policy), it selects and outputs an **action `A_t`**.
3. The **Environment** receives the action `A_t`. In response, it transitions to a new state `S_{t+1}` and generates a new reward signal `R_{t+1}`.
4. The cycle repeats: the new state `S_{t+1}` and reward `R_{t+1}` become the inputs (`S_t`, `R_t`) for the Agent in the next time step.
The vertical dotted line next to `R_{t+1}` and `S_{t+1}` visually separates the outputs of the Environment for the *next* time step from the inputs for the *current* time step, emphasizing the discrete, step-wise nature of the process.
### Key Observations
* **Closed-Loop System:** The diagram forms a perfect, continuous loop, highlighting that reinforcement learning is an ongoing process of interaction, not a single computation.
* **Asymmetric Information Flow:** The Agent only receives *evaluative* feedback (reward `R_t`) and *descriptive* feedback (state `S_t`). It does not receive direct instructions. The Environment, in turn, only receives commands (action `A_t`).
* **Temporal Notation:** The consistent use of subscripts `t` and `t+1` is critical. It formally defines the sequence: the agent's action at time `t` causes the environment to produce outputs for time `t+1`.
* **Component Isolation:** The Agent and Environment are cleanly separated, emphasizing that the learning algorithm (inside the Agent) is distinct from the problem dynamics (inside the Environment).
### Interpretation
This diagram is the canonical representation of the **agent-environment interface** in reinforcement learning. It is not a chart with empirical data but a conceptual model that defines the problem framework.
* **What it Demonstrates:** It establishes the core RL paradigm: an agent learns to make decisions by trial and error through direct interaction with an environment. The goal of the agent is to learn a policy (a mapping from states to actions) that maximizes the cumulative reward it receives over time.
* **Relationships:** The relationship is purely transactional and sequential. The Environment sets the "problem" (via states and rewards), and the Agent proposes a "solution" (via actions). The quality of the solution is judged by the reward signal, which is the only direct feedback the agent gets on its performance.
* **Notable Implications:**
* **The Reward Signal (`R_t`, `R_{t+1}`) is Central:** It is the sole indicator of success. The agent's entire objective is defined by this signal. The diagram shows it flowing directly to the agent, separate from the state.
* **The State (`S_t`, `S_{t+1}`) is the Agent's Perception:** It represents all the information the agent uses to make its decision. The diagram implies the agent has no access to the internal workings of the environment, only to these state signals.
* **The Action (`A_t`) is the Agent's Only Influence:** The agent cannot directly change the state or reward; it can only influence them indirectly by performing actions that the environment then processes.
In essence, this diagram provides the foundational "grammar" for all reinforcement learning problems. It answers the question: "What are the moving parts, and how do they talk to each other?" Any specific RL algorithm (like Q-learning or Policy Gradients) is a specific implementation of the "Agent" box in this diagram.