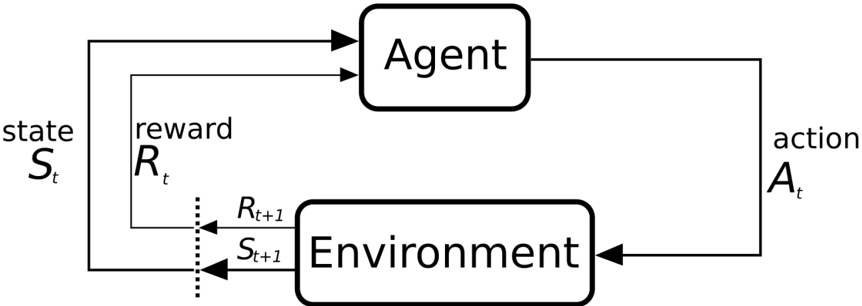
## Diagram: Reinforcement Learning Agent-Environment Interaction
### Overview
The diagram illustrates the core feedback loop in reinforcement learning, showing the interaction between an "Agent" and an "Environment." It depicts the sequential exchange of states, actions, and rewards, forming a cyclical process where the agent learns through trial and error.
### Components/Axes
1. **Agent**: Central processing unit that observes states, selects actions, and receives rewards.
2. **Environment**: External system that provides states and rewards based on the agent's actions.
3. **State (S_t, S_{t+1})**: Represented as rectangular boxes, indicating the agent's current and next observation of the environment.
4. **Action (A_t)**: Arrow from the agent to the environment, denoting the decision made by the agent.
5. **Reward (R_t, R_{t+1})**: Arrows from the environment to the agent, showing feedback on the action's effectiveness.
6. **Flow Direction**:
- Solid arrows: Primary data flow (state → action → next state/reward).
- Dashed arrows: Secondary feedback loop (reward influencing future actions).
### Detailed Analysis
- **State-Transition Flow**:
- The agent begins with state **S_t**, processes it to select action **A_t**.
- The environment transitions to state **S_{t+1}** and provides reward **R_{t+1}**.
- The reward **R_t** is explicitly labeled within the agent's processing box, suggesting it is used to update the agent's policy.
- **Reward Structure**:
- **R_t** (current reward) and **R_{t+1}** (next reward) are visually distinct but connected via dashed arrows, implying temporal dependency.
- Rewards are bidirectional between the environment and agent, emphasizing their role in shaping behavior.
### Key Observations
1. **Cyclical Nature**: The looped arrows confirm the iterative learning process central to reinforcement learning.
2. **Temporal Labeling**: Explicit use of **t** and **t+1** indices highlights the sequential decision-making framework.
3. **Reward Placement**: **R_t** is embedded within the agent's box, while **R_{t+1}** originates from the environment, suggesting a design choice about reward attribution.
### Interpretation
This diagram abstracts the reinforcement learning paradigm into its fundamental components:
- **Agent-Environment Symbiosis**: The agent's actions directly shape the environment, while the environment's feedback (states/rewards) drives the agent's learning.
- **Reward as Learning Signal**: The explicit inclusion of **R_t** within the agent's processing box implies that immediate rewards are used to update the policy, while **R_{t+1}** may represent delayed feedback for long-term planning.
- **State Abstraction**: The environment's states (**S_t**, **S_{t+1}**) are treated as black boxes, focusing on the agent's interaction rather than environmental complexity.
The diagram emphasizes the agent's role as an active learner, constantly adapting actions based on environmental responses. The separation of **R_t** and **R_{t+1}** suggests a potential distinction between immediate and delayed rewards, a critical consideration in designing reward-shaping strategies to avoid short-sighted behavior.